
submitted in partial satisfaction of the requirements for the degree Master of Science in Media Arts & Technology
2023-06-12
Committee in Charge:
Professor Curtis Roads (Chair)
Professor Jennifer Jacobs
Lecturer Karl Yerkes
The thesis of Nathan Blair is approved.
June 2023
Thank you to my committee, Karl Yerkes, Curtis Roads, and Jennifer Jacobs for guidance and inspiration.
Thank you to my collaborators, Jack Kilgore and Alec Denny, and to the many audio programmers who have inspired this work, including Timur Doumler, Sudara Williams, and Joshua Hodge.
Since the beginning of 2022 I have developed four audio plugins using the C++ framework JUCE. In doing so, I accumulated various strategies for enhancing the dependability and efficiency of my programs; for example, I learned to avoid memory allocation in the audio thread, refuse third party libraries, and refrain from invoking system calls. However, I also discovered specific circumstances where each of these principles was no longer desirable. Rather than relying on rules of thumb and general guidelines, I sought to develop a set of first principles for developing production-level audio software.
I argue that many good audio programming practices can be derived from the following fact: audio plugins are multi-threaded programs subject to a firm real-time constraint. With this framing in mind, I present The Template Plugin: a starting point for new plugin projects that integrates the best practices and creative solutions I have implemented in my own work. I justify the design of The Template Plugin by discussing effective strategies for thread synchronization, optimization, program state management, user interfaces, and build systems within the context of multi-threaded and real-time applications.
Audio software development integrates a diversity of specialized topics such as low level programming, signal processing, music theory, design, software engineering, and human perception. It is no wonder, then, that producing professional quality audio plugins can be prohibitively difficult for students, researchers, and independent developers. Likewise, I was out of my depth when I began developing audio software; many of my first programs were prone to glitches and crashing.

I eventually gained various strategies for enhancing the dependability and efficiency of my programs, such as avoiding memory allocation in the audio thread. Furthermore, I learned to justify these strategies by reasoning about the complex processes running in the background of my programs.
With newfound confidence, I began developing audio plugins using the JUCE framework. These plugins are exported in the VST3 and AU formats and can be opened in most professional digital audio workstations (DAWs). In order, these plugins are Karp, Pebble, Waveshine and Halo 3D Pan. Of these, Karp has been commercially released and downloaded over 4000 times by music producers, sound designers, audio engineers, and recording artists at the professional and hobbyist levels.
In this document I will present The Template Plugin, an open source codebase for starting new plugin projects. I will discuss strategies for successfully building on The Template Plugin based on the main hurdles and solutions that I have encountered developing plugins. In particular, I will discuss real-time programming, optimization, parameter management, inter-thread communication, and build systems.
The developer who will most benefit from The Template Plugin already has a good understanding of audio algorithms, but does not know how to package their algorithms in a finished product for others to use. I hope this work will be particularly useful to other graduate students looking for a high impact way to release their research projects into the world. Releasing audio code in a real-time plugin can lead to powerful feedback and new collaborations. In my opinion, a plugin is the best way to get new audio algorithms into the hands of a large community of music producers.
Before diving into the details of audio plugins, it is important to understand a few of the fundamental concepts of digital audio.
A plugin host is any program that can open an audio plugin. For example, Cycling74’s Max/MSP, Apple’s GarageBand, and Adobe Premiere Pro are all plugin hosts. Each of these programs have very different use cases, but they all allow synthesis and/or editing of audio with 3rd party plugins.
The most common type of plugin host – and the most common tool for producing music on a computer – is a Digital Audio Workstation (DAW). A DAW is a piece of software that allows users to record, edit, and mix audio. DAWs are used to produce music, podcasts, soundtracks, and other audio content. GarageBand, Ableton Live, and FL Studio are all examples of DAWs.

A typically DAW contains many tracks, each of which contain either audio or MIDI data. Audio data is either recorded directly into the DAW or loaded from an audio file. A MIDI track contains a sequence of MIDI notes that are sent through a virtual instrument or hardware synthesizer to produce sound. Each track contains a number of clips, which are sections of audio or MIDI data that are arranged on a timeline to be played back at a specific time. Clips can be moved around, cut, copied, and pasted.
Virtual instruments are pieces of software that synthesize audio from MIDI data. Virtual instruments can trigger audio samples, synthesize audio from scratch, or do a combination of both. Furthermore, DAWs typically support audio effects, which are added to tracks to apply filters, reverb, distortion, or other sound transformations to incoming audio. Both virtual instruments and audio effects can be bundled with the DAW or installed separately as audio plugins.
Digital audio is represented as a sequence of discrete floating point numbers called samples. Each sample represents the amplitude of the audio signal at a specific point in time. Note that it is also common to refer to larger clips of audio as samples; in the context of digital signal processing, though, samples typically refer to a single amplitude value in a waveform. During playback, programs read audio samples to the output hardware at the sample rate, which is commonly 44100 Hz.

Rather than processing each sample individually, host programs process audio in blocks: sequences of samples that are processed as a unit. The size of a block is called the buffer size or block size. Increasing the buffer size allows the DAW to process more samples at once, reducing the time spent on overhead, and decreasing the chance that the DAW is not able to serve the audio hardware in time. There is a trade-off, however: increasing the buffer size introduces latency to the system. Because of this, it is common to use low buffer sizes while recording to reduce latency, and higher buffer sizes while mixing and editing when more processing power is required.
All audio plugins should be able to adapt to the buffer size and sample rate of the host. That is, the plugin should sound the same no matter the sampling rate and buffer size, as much as possible.
While audio plugins need to adapt to the host buffer size, certain plugins may request additionally latency to perform their calculations. This allows the plugin to process blocks internally at a larger buffer size, which can be useful for certain algorithms such as the fast Fourier transform.
It’s useful to imagine two separate threads of execution interacting with any audio plugin: the audio thread and the message thread. While the operating system may use more or less actual threads, this simplified model is enough to write plugins that are thread-safe. Importantly, it is safe to assume that no more than two threads will be accessing the plugin data at any given time, unless you intentionally create extra threads.

The audio thread is responsible for processing audio samples and is run at a high priority. It is scheduled to run as consistently as possible and processes a single block of audio each time it is called. When the audio thread does not finish running in time to serve the audio hardware, the behavior is undefined – typically, the audio hardware will repeat the last block of audio it received or serve all zeros until the audio thread is able to catch up, resulting in an audible glitch.
The message thread is responsible for handling user input and drawing the graphical user interface. It is typically run at a lower priority than the audio thread. One must be careful when sharing data between the message thread and the audio thread: accessing data from multiple threads simultaneously is a race condition and can lead to undefined behavior, audio glitches, and crashes.
Most audio plugins have a similar high level interface. They produce audio at a given sample rate, have a GUI, and, in the case of an effect plugin, may also take audio as input. However, the exact details of this interface are defined by one of many particular audio plugin formats. To maximize compatibility with different hosts, developers export and release their plugins in a variety of formats.
There is no unified format for audio plugins. It is up to host DAWs to decide which plugin formats they will officially support. There are, however, a few commonly supported plugin formats that most DAWs accept.
| Format | MacOS | Windows | Linux | Ableton Live | FL Studio | Logic Pro | Pro Tools | Audacity | Reaper | Reason |
|---|---|---|---|---|---|---|---|---|---|---|
| VST | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| AU | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| AAX | ✓ | ✓ | ✓ | |||||||
| LV2 | ✓ | ✓ | ✓ | ✓ | ✓ |
VST – Virtual Studio Technology is a proprietary plugin format developed by Steinberg Media Technologies. It is widely supported and is probably the most popular audio plugin format. The latest version of VST is VST3; earlier versions, VST and VST2, are being phased out. VST plugins are supported on MacOS, Windows, and Linux.
AU – Audio Unit is a proprietary plugin format developed by Apple. It is optimized for running on Apple computers and is the only plugin format supported by the DAW Logic Pro. The latest Audio Unit standard is AUv3.
AAX – Avid Audio Extension is a proprietary plugin format developed by Avid Technologies and is the successor to their Real Time AudioSuite (RTAS) format. AAX plugins are only supported in Pro Tools, and likewise, Pro Tools only supports AAX plugins.
LV2 – Linux Audio Developer’s Simple Plugin API Version 2 is an open and permissively licensed format for audio plugins. However, LV2 is supported by a relatively small number of hosts. It is typically built to run on Linux machines, though can be built on other operating systems in certain circumstances.
Audio plugins can also be built as standalone applications that run as executables. In this case, they exchange audio with a hardware source, like a microphone, directly rather than with a host application.
Because there is no universal audio plugin format, developers create multiple versions of their software to support different users. Plugin frameworks like JUCE (Jules’ Utility Class Extensions, named after the original developer Jules Storer) make this process relatively painless; developers can write code in JUCE and export it to many different formats.
This is not an exhaustive list of plugin formats. For example, Bitwig recently introduced CLever Audio Plug-in, or CLAP, and Ableton supports Max for Live plugins. These other formats cannot be exported with JUCE, however, and are in general not widely supported.
While it is possible to develop for a particular audio plugin format directly using that format’s software development kit (SDK), it is much more common to use a framework for developing plugins. No other framework is as popular as JUCE.
According to the JUCE website, “JUCE is the most widely used framework for audio application and plug-in development. It is an open source C++ codebase that can be used to create standalone software on Windows, MacOS, Linux, iOS and Android, as well VST, VST3, AU, AUv3, AAX and LV2 plug-ins” [1].
If you are looking for a JUCE alternative, Oli Larkin’s iPlug 2 provides a more liberal licensing system but also has limited features and support [2]. The rest of this manuscript will discuss developing plugins with JUCE.
Writing reliable and performant audio code necessitates precise control of application memory and low-level knowledge of algorithmic complexity. As such, audio programs often require custom low-level code, best written in a language like C.
Despite this, JUCE is a high level, bulky, and only occasionally well-documented framework. Why use a framework at all? Well, then you would have to interact with prohibitively complex audio format SDKs and operating system libraries.
My preference is to use JUCE only for what it excels at. For everything else, I go low level, and write custom algorithms in C and C++.
JUCE framework functionality that I rely on includes:
JUCE framework functionality that may be unreliable, slow, badly documented, or poorly suited for a particular plugin includes:
In other words, I prefer to use JUCE for boilerplate code, and use C++ directly for application-specific code as much as possible. Digital signal processing code is particularly well suited for custom algorithms written in C or C++.
Audio plugins are subject to a real-time constraint. That is, they promise to output audio samples faster than the speaker produces sound. Unfortunately, this rules out many programming techniques from non-real-time contexts. In this section, I examine the consequences of the real-time constraint, especially in the context of complex multi-threaded applications.
If a program satisfies the real-time constraint, it is considered real-time safe. That is, a real-time safe audio program provides a reasonable guarantee that it will output audio on time. Here, reasonable means that the program will always satisfy the real-time constraint under normal operating conditions on a target machine. In practice, it is sufficient that any real-time operation uses a small and deterministic number of CPU cycles in the worst case.

What happens when the real-time constraint is not satisfied? As I noted discussing the audio thread, this behavior is undefined and often leads to an audible glitch. Even infrequent glitches can damage the reputation and usability of an audio plugin. The possibility of a single glitch during a live show is enough to render the audio plugin useless in a concert setting and will dissuade engineers and performers from using it.

How much time do audio programs actually have to satisfy the real-time constraint? To analyze this, consider the CPU budget of the audio callback: the number of CPU cycles that the audio callback has before running out of time and causing a glitch. Given the sampling rate, number of channels, CPU clock speed, and buffer size, the CPU budget can be estimated with the following equation:
\[\text{CPUBudget} = \frac{\text{clockSpeed}*\text{bufferSize}}{\text{samplingRate} * \text{numChannels}}\]
Let’s assume the worst: a very slow CPU – perhaps an embedded device – with a clock speed of \(100\) MHz, using a very high sampling rate of \(192\)kHz, and two channels. We can set bufferSize to one to get the maximum number of cycles allowed per sample.
\[\text{CPUBudget} \approx \frac{100 * 10^6\frac{instruction}{second}}{192 * 10^3 \frac{samples}{second} * 2} \approx 260 \frac{\text{CPU cycles}}{\text{sample}}\ \text{(on a slow machine)}\]
If we assume a typical buffer size of \(256\) samples, each audio callback must complete in around \(260 * 256 = 66560\) cycles, or roughly \(1.3\) milliseconds. In this dramatic worst case, only extremely fast algorithms can meet the real-time constraint.
Fortunately, modern CPUs have much higher clock speeds – typically around \(3\) to \(5\) GHz – and audio programs often run at much lower sampling rates – often \(44.1\) kHz. Thus, under typical operating conditions:
\[\text{CPUBudget} \approx \frac{3.5 * 10^9\frac{instruction}{second}}{44.1 * 10^3 \frac{samples}{second} * 2} \approx 4*10^4 \frac{\text{CPU cycles}}{\text{sample}}\ \text{(on a modern machine)}\]
Here is another factor to consider: on a modern computer, it is common for many plugins to run at the same time. In the case where the user is running 10 plugins at once – very common for large production products – our CPU budget is reduced by 10x, bringing our CPU Budget from 40,000 to just 4,000 cycles per sample.
Audio callbacks must stay within their CPU budget 100% of the time. While a typical programmer is concerned with average runtime, audio programmers must be concerned with worst-case runtime.
Some relief is provided by processing large audio blocks rather than single samples at a time. This can reduce per-callback overhead and improve cache performance. Still, real-time audio callbacks must be extremely efficient.
To guarantee real-time safety it is essential to avoid any blocking or otherwise unbounded runtime code in the audio callback. Any code that might take a long time to run, even in rare circumstances, has the potential to cause an audio glitch. Applying this principle rules out many common programming techniques. On the other hand, developing an understanding of which techniques invalidate real-time safety provides a foundation for consistently writing reliable audio programs.
Audio plugins rely heavily on inter-thread communication. For example, plugin parameters and loaded sound files are passed from the interface to the audio thread; furthermore, loudness and spectrum information may be passed from the audio thread to the interface. Without proper care, concurrent data access can lead to data races, synchronization issues, and crashes.
In non-real-time contexts, data sharing is often safely implemented using mutexes and locks, programming structures which prevent synchronous access to data between threads. In particular, a mutex can be captured by one thread at a time to prevent critical sections of code from running simultaneously. However, using mutexes and locks in the audio callback is not real-time safe for a number of reasons.
Consider the following case. The audio thread is attempting to capture a mutex, but fails – the mutex is already locked by the message thread. Now the audio thread must wait for the message thread to finish. This is already problematic, as it requires one to write real-time safe code within the locked critical section of their message thread. Even worse, though, missing the lock may trigger a system call from within the audio thread, as the audio thread may attempt to place itself in a sleep queue until the mutex becomes free.
Even if the message thread needs only to execute an efficient, real-time safe operation and the lock is implemented without sleeping, there is still the danger of priority inversion. Since the message thread is typically running at a low priority, the operating system may interrupt execution of the locked critical section, stalling both threads. In other words, the high priority audio thread will be reduced to the priority of the thread it is waiting on if it fails to capture a mutex.

One possible solution is to use a non-blocking try-lock, which simply moves on instead of blocking when it is not able to capture a mutex. While try-locks may result in missing or late data, at least they will not block the audio thread. Unfortunately, however, try-locks are rarely real-time safe out of the box. While a failed try-lock is real-time safe, a successful try-lock may not be. Consider this case: the audio thread captures a mutex using a try-lock, and begins executing the critical section. Simultaneously, the message thread fails to capture the same mutex and sleeps while it waits on the audio thread. When the audio thread finishes the critical section, it releases the mutex and wakes up the message thread. This wake-up call is a system call that is not guaranteed to be portably real-time safe.
Put simply, locks have the potential to block the audio thread from processing samples. This can reduce the CPU budget of the audio callback and lead to a glitch. To implement inter-thread communication without locks, see the solutions in my discussion on thread synchronization
Operating system calls, or simply system calls, are any operations which request a service from the operating system. Types of system calls include allocating and freeing memory, creating processes, waiting, creating files, opening/closing files, accessing system information such as time and computer name, generating random numbers, and printing to the console. In order to handle requests from many processes, system calls may internally use locks and other blocking mechanisms. Moreover, many system calls are optimized for average runtime – with a very slow worst case runtime.
While some real-time operating systems have been developed for real-time constrained contexts such as air-traffic control, heart pace-makers, and self driving cars, common modern operating systems (MacOS, Windows, Linux, etc.) are not optimized for real-time. Thus, operating system calls should be avoided in the audio callback, as they may take an unbounded amount of time to complete.
Memory allocation and deallocation, such as with C++ keywords
new, free, malloc, or
delete, may trigger operating system calls that block the
audio thread. Furthermore, many common allocators use locks internally
to protect the memory they are modifying. In certain cases, memory
allocators may wait for the OS to bring in memory from disk, which is
very slow. And, even algorithms for deciding how to allocate a block of
memory may run in unbounded time. While it is possible to implement
real-time safe memory allocators and deallocators, default allocators
should be avoided in the audio callback.
To avoid memory allocation, one can pre-allocate all of the memory they will need. Then, within the audio callback, it is safe to capture and release chunks of pre-allocated memory as needed. To accomplish this, it is important to limit the maximum amount of memory needed at any given time. To ensure the user doesn’t request more memory than is have preallocated, one may need to limit the types of algorithms used – say, by setting a maximum number of voices in a synthesizer or a maximum number of filters in an effect plugin.
Programming libraries abstract complicated algorithms with simple wrapping functions. As such, many programmers rely on library code; it is easier and more reliable to use library code than to implement everything from scratch. This is considered best programming practice in most other contexts, as library code is more likely to be bug-free and optimized.
However, there is a problem with library code in audio programming. Most library code is not guaranteed to be real-time safe – including C++ standard library code and even JUCE code. Since real-time safety is a niche concern, library documentation rarely comments on lock usage, memory allocation, system calls, or any of the other things that are forbidden in real-time code. Often, the only ways to determine if a function is real-time safe is reading the code or avoiding libraries all together.
Consider the JUCE AudioBuffer class: a basic building
block used in JUCE audio callback code. The AudioBuffer is
a simple data structure consisting of one or more arrays filled with
audio sample information. Despite AudioBuffer’s usage on
the audio thread, its setSize method may allocate
additional memory to expand the size of the buffer’s internal arrays. To
JUCE’s credit, this method does include a flag,
avoidReallocating, which prevents this behavior. Still,
beginners who do not know the danger of reallocating in the audio
callback may not know to set this flag, which is off by default.
Here is a more insidious example of dangerous library code in JUCE.
JUCE’s SliderParameterAttachment class synchronizes plugin
parameters with UI sliders; on any parameter change,
SliderParameterAttachment will update the UI slider’s
internal state and vice versa. The problem is, parameter changes can
come from both the message thread and the audio thread. These changes
trigger the SliderParameterAttachment method
parameterValueChanged, which if called from the audio
thread, invokes triggerAsyncUpdate;
triggerAsyncUpdate may make a blocking system call. The documentation
for triggerAsyncUpdate warns:
“It’s thread-safe to call this method from any thread, BUT beware of calling it from a real-time (e.g. audio) thread, because it involves posting a message to the system queue, which means it may block (and in general will do on most OSes)” [3].
So, using the JUCE SliderParameterAttachment is not necessarily real-time safe, as it may trigger a blocking system call. Despite this, JUCE’s own tutorials encourage using the parameter attachments [4].
Libraries besides JUCE often include even more real-time safety
traps. The C++ standard library, for example, specifies nothing about
execution time, memory allocation, or lock usage. Most standard library
algorithms happen to be real-time safe, but there are notable exceptions
including std::stable_sort. Since there is no standard
implementation of the standard library, determining which functions are
real-time safe comes down to carefully reading the documentation and
reasoning about likely implementation details. If there is any chance
that a function makes a system call or allocates memory, it is best to
avoid it.
In summary, be extremely careful using libraries on the audio thread. If you must, consider using a library specifically made for real-time code such as Timur Doumler’s Crill (Cross-platform Real-time, I/O, and Low-latency Library) [5].
There are many reasons to use random number generators in audio code
including noise generation, parameter modulation, and physical
simulations. System-level random number generators are out of the
question, however, for the same reasons as other system calls. What
about std::rand from the standard library? Unfortunately,
the std::rand implementation is unspecified and may contain
locks, system calls, or other undesirable behavior.
Instead, it is best to opt for a fast real-time safe pseudo-random number generator. JUCE’s random number generator is a good option; it may not contain the highest quality random numbers – that is, don’t use it for cryptography – but it is perfectly suitable for audio applications [6]. The source code for JUCE’s implementation is as follows:
int Random::nextInt() noexcept
{
seed = (int64) (((((uint64) seed) * 0x5deece66dLL) + 11) & 0xffffffffffffLL);
return (int) (seed >> 16);
}Other real-time safe random number generators include the standard
libraries linear_congruential_engine and the very efficient
Xorshift algorithm [7],
[8].
Communicating with the outside world from within the audio thread requires special care. While it may be desirable to read an audio file from disk, control audio with an external device like the mouse, or even contact an online server, each of these scenarios require locks, memory allocation, and system calls. Instead, it is best to use a low priority thread for communicating with the outside world, and to take advantage of lock-free data structures to get information back into the audio thread. Atomics, lock-free FIFOs, and carefully constructed spin locks are applicable – I go into more details on these structures when discussing thread synchronization.
Certain algorithms, such as quicksort and hashmap lookups, are fast in general but slow in the worst case. These algorithms, which rely on statistical or amortized-time performance, should be avoided in the audio callback when possible. Recall that a single missed audio block will lead to an audible glitch.
There are a number of existing open source plugin projects and templates.
The Template Plugin is directly modified from the JUCE framework CMake
Audio Plugin Example, included in the JUCE library [9]. The CMake Audio
Plugin Example provides a minimal framework for exporting audio plugins
from JUCE with CMake. It comes with an
AudioPluginAudioProcessor class for handling interactions
with the audio thread and an
AudioPluginAudioProcessorEditor class for handling
interactions with the message thread. The CMake Audio Plugin Example is
minimal and unopinionated; it does not provide any system for parameter
management, leaving the developer to create their own real-time safe
state management system.
Pamplejuce is an open source JUCE Template that supports, along with CMake, a testing system with the Catch2 framework, C++20, and a GitHub Actions configuration for building cross platform, testing, and code-signing [10]. Pamplejuce is developed by Sudara Williams and is licensed under the MIT license. Pamplejuce builds on the JUCE CMake Audio Plugin Example by adding features necessary for distributing professional plugins. Compared to The Template Plugin, pamplejuce has a less opinionated approach for state management, using essentially the same source code as the JUCE CMake Audio Plugin Example with a more sophisticated build system.
Nicholas Berriochoa’s juce-template is an open source audio
plugin template which is most similar in scope to my Template Plugin
[11]. In
particular, Nicholas Berriochoa’s implementation includes logic for a
state management system that wraps plugin parameters and internal plugin
settings, as well as other useful features that go beyond The Template
Plugin such as react-js user interfaces, Rust-based digital signal
processing, testing, and key verification. While Nicholas Berriochoa
does use the AudioProcessorValueTreeState::SliderAttachment
class and listener systems, which I prefer to avoid for real-time safety
reasons, the juce-template project is still an incredible
resource for developers.
Surge XT is an award winning open source software synthesizer built in C++ with a JUCE-based user interface [12]. Surge XT is released under the GNU GPLv3 license, and is a powerful reference for the digital signal processing and design patterns that go into a commercial-quality product [13]. Surge XT supports a number of build platforms including MacOS, Windows, Linux, and Raspberry Pi. Furthermore, Surge XT can be built in the new CLAP plugin format.
valentine is an open source compressor plugin developed by
Jose Diaz Rohena [14]. It is a great example of a simple
plugin built using the JUCE framework. While valentine
incorporates some design patterns that I prefer to avoid, such as using
the AudioProcessorValueTreeState::SliderAttachment class,
it is still an extremely valuable reference project. valentine
is released under the GNU GPLv3 license.
Vital is a popular “spectral warping wavetable synthesizer” by Matt Tytel released under GNU GPLv3 [15]. Vital is a massive project built on JUCE but with mostly custom code in C++. Furthermore, Vital uses hardware accelerated graphics for performant and detailed visualization in the UI. Vital is a great resource for understanding how a large plugin project can be organized.
Developing my own system for writing audio plugins has relied heavily on numerous plugin development tutorials and resources.
JUCE provides a series of beginner friendly tutorials for getting started with plugin development using the JUCE library [16]. Unfortunately, some of these tutorials do not strictly adhere to the principals of real-time safe audio programming. Despite this, they are useful for developing an understanding of the JUCE framework. Furthermore, the JUCE forum contains a plethora of valuable questions and conversations between developers [17].
Joshua Hodge, better known as The Audio Programmer, has fostered a large community of audio developers around his YouTube and Discord channels. The Audio Programmer YouTube channel contains recordings of in-depth coding sessions and valuable interviews with developers [18]. Furthermore, The Audio Programmer Discord community is one of the best places to search for plugin development questions, as many topics have been addressed in the Discord that are not posted on online forums.
The Audio Developers Conference is an annual professional developers conference hosted by JUCE. Recordings of talks from the Audio Developers Conference are posted online at the JUCE Youtube channel – these talks are an essential resource for understanding some of the more subtle aspects of audio programming, such as real-time safe programming, distribution, testing, and new approaches [19].
Timur Doumler’s talk on thread synchronization in real-time audio processing and Fabian Renn-Giles and Dave Rowland’s talk Real-Time 101 have been essential to my understanding of real-time programming and the development of this project [20], [21]. Timur Doumler has also released an open source library of low-latency real-time programming in C++, Crill, which implements some of the more sophisticated thread synchronization algorithms that I discuss in this paper. For another great reference on real-time safe audio programming, see Ross Bencina’s blog post Real-Time Audio Programming 101: Time Waits for Nothing [22].
Sudara Williams’ blog provides a number of detailed tutorials on optimizing, profiling, and testing audio plugins [23]. This blog has informed my understanding of the JUCE repainting system and the best ways to profile plugin projects.
The second edition of The Computer Music Tutorial by Curtis Roads is a comprehensive and essential reference for all aspects of computer music [24]. Furthermore, Julius O. Smith has a number of books and tutorials that are freely available online about physical modeling, digital filters, and other digital signal processing topics [25]–[28]. The comprehensive DAFX book is another useful reference for implementing digital audio effects [29].
Finally, Oli Larkin’s More Awesome Music DSP, Jared Drayton’s Audio Plugin Development Resources, and Sudara William’s Awesome Juce are comprehensive lists of resources for audio programmers, which go well beyond the scope of this paper and include a number of additional references [30]–[32].
Since 2022 I have developed four audio plugins using the JUCE framework. In this section, I will describe each of these plugins and touch on some of their unique features. I will discuss some of the challenges I encountered when making each of these plugins, and conclude by introducing an open source template for JUCE plugins.
Karp is a virtual instrument for synthesizing plucked strings. It was released as an audio plugin in July of 2022 in VST3 and AU formats and has been downloaded over 4000 times. To play Karp, the user triggers notes with either a MIDI keyboard or sequenced MIDI from a host program. Karp is a polyphonic synthesizer, and supports up to 128 simultaneous notes.
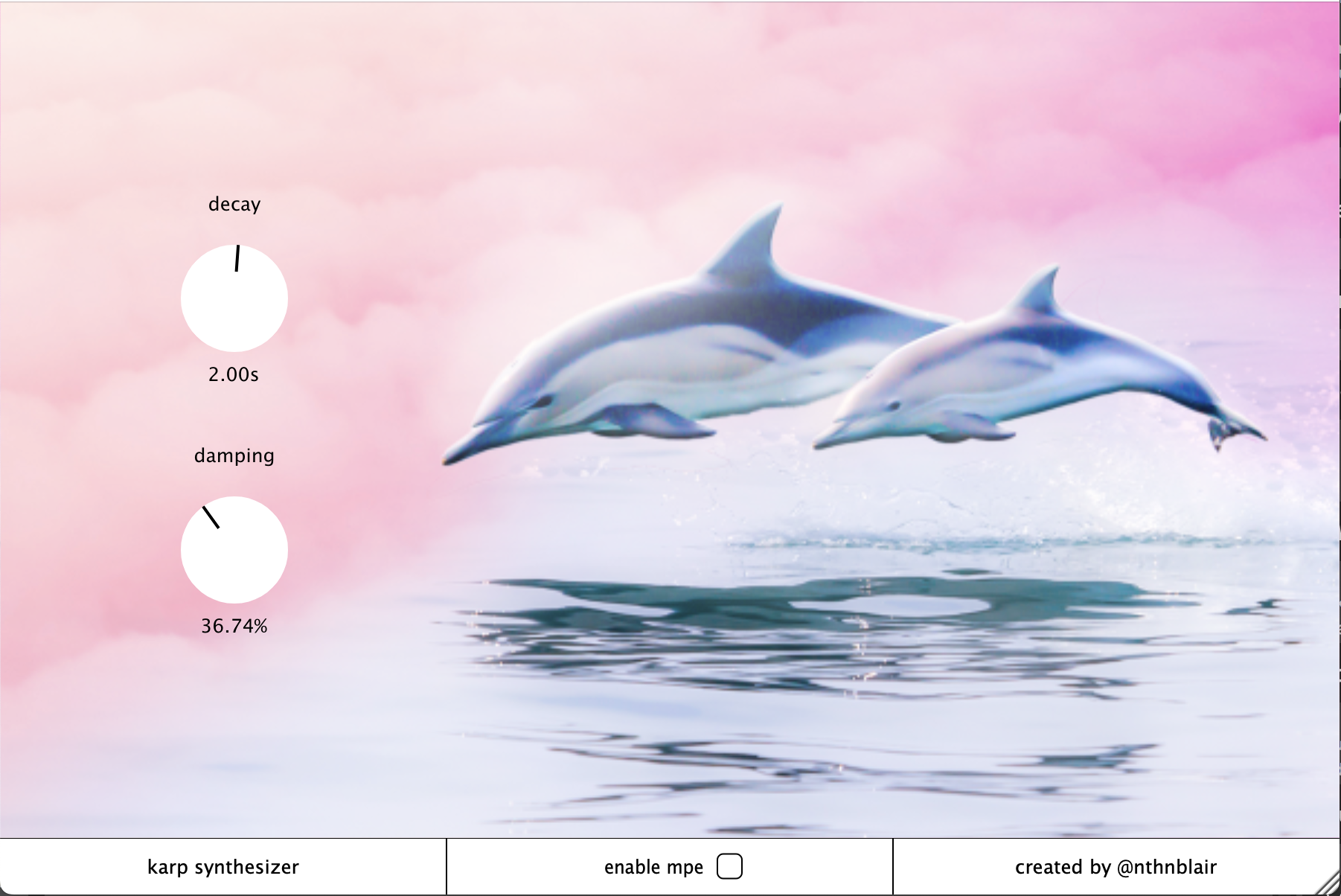
Karp is based on the classic Karplus-Strong algorithm, a “cheap to implement, easy to control, and pleasant to hear” technique for creating string sounds devised by Alex Strong in 1978 [33]. In particular, Karp implements extensions of the original Karplus-Strong algorithm proposed by Jaffe and Smith to control the tuning, decay time, and damping of the sound [34].
The Karp interface is intentionally simple, with just two knobs. The first knob controls the decay time of the plucks in seconds, while the second knob controls the damping: how much the pluck is muted by the internal low pass filter. There is also a button to enable/disable midi polyphonic expression (MPE) – allowing the user to switch between traditional and polyphonic pitch bend capabilities depending on the needs of their project.

My implementation of the Karplus-Strong algorithm includes a biquad filter in the delay line to control the damping of the sound. Compared to the moving average filter in the original Karplus Strong implementation, the biquad filter provides richer, more dynamic control of the damping of the virtual string. However, the placement of the biquad filter inside of the feedback loop also introduces a small group delay dependent on the filter cutoff. This changes the effective length of the delay line and knocks the synthesizer out of tune for certain settings. To rectify this, I modify the length of the delay line based on the cutoff of the biquad filter. I match the effective delay length to the desired pitch using a lookup table that associates filter cutoff values with a number of samples to offset the delay length. This was an effective solution with minimal computational overhead.
The classic Karplus Strong algorithm uses white noise as an impulse for the feedback system to generate plucked strings sounds. In my experiments, the sound generated by the white noise impulse had a thin, metallic timbre and harsh transient. This was desirable for bright and undamped plucks, but undesirable in the damped setting. My solution comes from Peter Schoffhauzer’s “Synthesis of Quasi-Bandlimited Analog Waveforms Using Frequency Modulation” [35]. Based on Schoffhauzer’s work, I efficiently generate impulse responses with various spectral qualities using frequency modulation. The result is a single cycle saw-like impulse that transitions from a filtered waveform with few harmonics to one that is noisy and spectrally complex depending on the damping parameter. This enables users to generate smooth, woody timbres in the damped setting.
While Karp’s knobs and buttons are rendered on the CPU, the background image is rendered as a GLSL shader on the GPU. The background doubles as an audio visualizer – a ripple effect is triggered on each new note. Multiple ripples can be triggered at once, which interfere with each other to create a rich effect that evokes gentle waves in a shallow pool. The visuals are intended to complement the tranquil sounds of plucked strings and provide a pleasant user experience. The background image of two dolphins in front of pink clouds was created by digitally collaging royalty free stock images.

Waveshine is a reverb/delay plugin that uses an 8 channel feedback delay network to create a rich, spatial sound. It was created in collaboration with Alec Denny and is unreleased. Depending on the settings, Waveshine can be used as a reverb, a delay, or a combination of the two. It has built in auto-pan and filter effects for additional sound design opportunities.
Feedback Delay Networks (FDNs) are a class of parametric reverberation algorithms that exploit multiple delay lines of different length in parallel [28]. These delay lines are mixed together via a diffusion matrix and fed back into themselves. This roughly simulates sound waves reflecting off of walls in a room and mixing in the air around a listener. In this way, FDNs can be compared to raytracing reverberation algorithms, which calculate exact paths of sound rays through a 3D simulated environment. Unlike raytracing reverbs, however, FDNs do not accurately simulate real world environments; because of this, they are much more computationally efficient.

Feedback delay networks have two critical parameters: the lengths of each delay line and the entries in the diffusion matrix.
The relative lengths of the delay lines determine the frequency response of the reverb. It is often musically desirable for the FDN to have a flat frequency response, which prevents resonances in the output. To achieve this, the length of delay lines should be chosen to be co-prime, meaning that they do not share any common factors. This rule “maximizes the number of samples that the lossless reverberator prototype must be run before the impulse response repeats” [28].
Using mutually prime delay lengths given desired delay lengths requires a fast algorithm for finding co-prime numbers. Since prime numbers are relatively dense, it is sufficient to use only prime number delay lengths. With this constraint, one can precompute all prime numbers less than the maximum delay length and then select prime numbers from the list that are nearest to the desired delay lengths. This can be implemented efficiently using binary search. In Waveshine, the Scatter parameter controls the relative lengths of each delay line given the maximum delay. Users can modulate the Scatter parameter to interpolate between delay lines that are all the same length, evenly spaced across a range, or exponentially distributed across a range.
The diffusion matrix determines how delay lines are mixed. Combined with a feedback gain parameter, the diffusion matrix forms the feedback path of the audio signal within the FDN.
In order to control the decay of the reverb, it is important that the diffusion matrix is stable. This means that the Euclidean norm of the input signal is preserved as it passes through the diffusion matrix. To formalize this, one can constrain the diffusion matrices to unitary matrices, which by definition preserve the norm of input vectors. These matrices are sometimes referred to as lossless feedback matrices [28].
Two instructive examples of diffusion matrices are the identity matrix and the Hadamard matrix. The identity matrix simply passes the delay lines through without any mixing. In an 8 channel FDN, this corresponds with 8 individual delay lines acting in parallel. In practice, this can create clean delay signals that do not mesh into a reverb tail. Instead, the individual delay lines are heard as distinct echoes. On the other hand, the Hadamard matrix is an example of a maximally mixing and scattering diffusion matrix. With Hadamard diffusion, the feedback input to each delay line is comprised of an equal combination of each of the output delay lines. For a reverberant sound, it is typically desirable to have maximal mixing and scattering. This ensures that it is difficult for the listener to hear the sound of individual delay lines. Both the identity and Hadamard matrices are unitary matrices, and thus do not change the magnitude of the signal as it passes through the delay line.
In Waveshine, I desired a unitary feedback matrix that could be parameterized to smoothly transition between an identity matrix and a maximally mixed diffusion matrix. A naive solution linear interpolates between the identity and Hadamard matrices. In practice, however, this corresponds to a simple crossfade between the maximally mixed reverb sound and the minimally mixed delay sound, and does not in general preserve the unitary property of the diffusion matrix. I gained intuition from the case with only two delay lines. In that simple case, a valid 2x2 diffusion matrix that transitions between the identity and a maximally mixed state is the 2x2 rotation matrix. A 45 degree rotation corresponds with a maximally mixed diffusion, while a 0 degree rotation corresponds with the identity. To scale this up to the 8x8 case, I use the tensor product of three identical 2x2 rotation matrices. This creates a 8x8 matrix that is parameterized by a single mixing parameter, \(\theta\), and transitions smoothly between the identity and a maximally mixing diffusion matrix.
\[\text{Rot}_{2x2}(\theta) = \begin{bmatrix} \cos{\theta} & -\sin{\theta}\\ \sin{\theta} & \cos{\theta}\\ \end{bmatrix} \]
\[D_{8x8}(\theta) = \text{Rot}_{2x2}(\theta)\otimes\text{Rot}_{2x2}(\theta)\otimes\text{Rot}_{2x2}(\theta) \]
There is a subtle connection between Waveshine’s diffusion matrix and the field of quantum computing. In particular, Waveshine’s diffusion matrix corresponds with a quantum operation on a three qubit system that applies the same 2x2 rotation matrix, parameterized by an angle theta, to each qubit.
The 8x8 tensor product of three 2x2 rotation matrices is very efficient to compute. Importantly, while the waveshine diffusion matrix has 64 entries, each of those entries takes only one of 7 values. In fact, given an angle theta, the entire diffusion matrix can be computed with just 2 calls to sine/cosine and 6 multiplications. This makes it very efficient to compute waveshine’s diffusion matrix in realtime.
\[D_{ij} \in \{\cos^3(\theta), \pm\sin^3(\theta), \pm\cos(\theta)\sin^2(\theta), \pm\sin(\theta)\cos^2(\theta)\}\]
I exploit the simple structure of Waveshine’s diffusion matrix to efficiently perform the necessary feedback matrix multiplication in realtime. While a naive matrix multiplication requires 64 multiplications and 56 additions, the Waveshine diffusion matrix multiplication can be reduced to 32 multiplications and 48 additions.
\[\begin{bmatrix}a & - b & - b & c & - b & c & c & - d\\b & a & - c & - b & - c & - b & d & c\\b & - c & a & - b & - c & d & - b & c\\c & b & b & a & - d & - c & - c & - b\\b & - c & - c & d & a & - b & - b & c\\c & b & - d & - c & b & a & - c & - b\\c & - d & b & - c & b & - c & a & - b\\d & c & c & b & c & b & b & a\end{bmatrix}\begin{bmatrix}v_{1}\\v_{2}\\v_{3}\\v_{4}\\v_{5}\\v_{6}\\v_{7}\\v_{8}\end{bmatrix}=\begin{bmatrix}a v_{1} - b v_{2} - b v_{3} - b v_{5} + c v_{4} + c v_{6} + c v_{7} - d v_{8}\\a v_{2} + b v_{1} - b v_{4} - b v_{6} - c v_{3} - c v_{5} + c v_{8} + d v_{7}\\a v_{3} + b v_{1} - b v_{4} - b v_{7} - c v_{2} - c v_{5} + c v_{8} + d v_{6}\\a v_{4} + b v_{2} + b v_{3} - b v_{8} + c v_{1} - c v_{6} - c v_{7} - d v_{5}\\a v_{5} + b v_{1} - b v_{6} - b v_{7} - c v_{2} - c v_{3} + c v_{8} + d v_{4}\\a v_{6} + b v_{2} + b v_{5} - b v_{8} + c v_{1} - c v_{4} - c v_{7} - d v_{3}\\a v_{7} + b v_{3} + b v_{5} - b v_{8} + c v_{1} - c v_{4} - c v_{6} - d v_{2}\\a v_{8} + b v_{4} + b v_{6} + b v_{7} + c v_{2} + c v_{3} + c v_{5} + d v_{1}\end{bmatrix}\]
\[\text{such that}\] \[a = \cos^3(\theta), b = \sin(\theta)\cos^2(\theta), c = \cos(\theta)\sin^2(\theta), d = \sin^3(\theta)\]
Notice that repeated entries in the resulting matrix can be computed once. Furthermore, using single instruction multiple data (SIMD) instructions for vectorizing the computation simplifies the process to 8 vectorized multiplications and 9 vectorized additions.
\[\begin{bmatrix}a \vec{v_1} + b\vec{x} - c\vec{y^\prime} + d \vec{v_2^{\prime}}\\a \vec{v_2} + b\vec{y} + c\vec{x}^\prime - d \vec{v_1^{\prime}}\end{bmatrix}\] \[\text{such that}\] \[\vec{v_1} = \begin{bmatrix}v_{1}\\v_{2}\\v_{3}\\v_{4}\end{bmatrix}, \vec{v_2} = \begin{bmatrix}v_{5}\\v_{6}\\v_{7}\\v_{8}\end{bmatrix}, \vec{l} = \Bigg(\begin{bmatrix}v_2 \\ v_1 \\ v_6 \\ v_5\end{bmatrix} - \begin{bmatrix}v_3 \\ v_4 \\ -v_7 \\ v_8\end{bmatrix}\Bigg), \vec{x} = \Bigg(\begin{bmatrix}-l_1 \\ l_2 \\ l_2 \\ l_1\end{bmatrix} - \vec{v_2}\Bigg),\vec{y} = \Bigg(\vec{v_1} + \begin{bmatrix}-l_3 \\ l_4 \\ l_4 \\ l_3\end{bmatrix}\Bigg)\] \[\text{and the prime symbol, }^\prime\text{, represents the following reordering operation}\] \[\begin{bmatrix}w_1 \\ w_2 \\ w_3 \\ w_4\end{bmatrix}^\prime = \begin{bmatrix}-w_4 \\ w_3 \\ w_2 \\ -w_1\end{bmatrix}\]
Waveshine’s user interface is designed to be intuitive and easy to use. Bright colors separate different sections of the GUI into distinct modules. Furthermore, the user is given tooltip hints when hovering over different parameters. Diffusion and feedback parameters are visualized in real time using a GLSL shader with visual feedback and diffusion metaphors. The user is also given the option to save and load presets, and to randomize the parameters of the plugin.
Pebble is a plugin for writing audio reactive shaders. Its functionality is similar to https://shadertoy.com – users can compose fragment shaders, compile them, and save them from within the program [36]. Since Pebble is integrated in a host audio program, users can create audio reactive visuals that are synchronized with their music. Users can then share their visuals on social media, or use them in live performances. In other words, Pebble is a potent live-coding tool for creating visuals in realtime from within a music session.
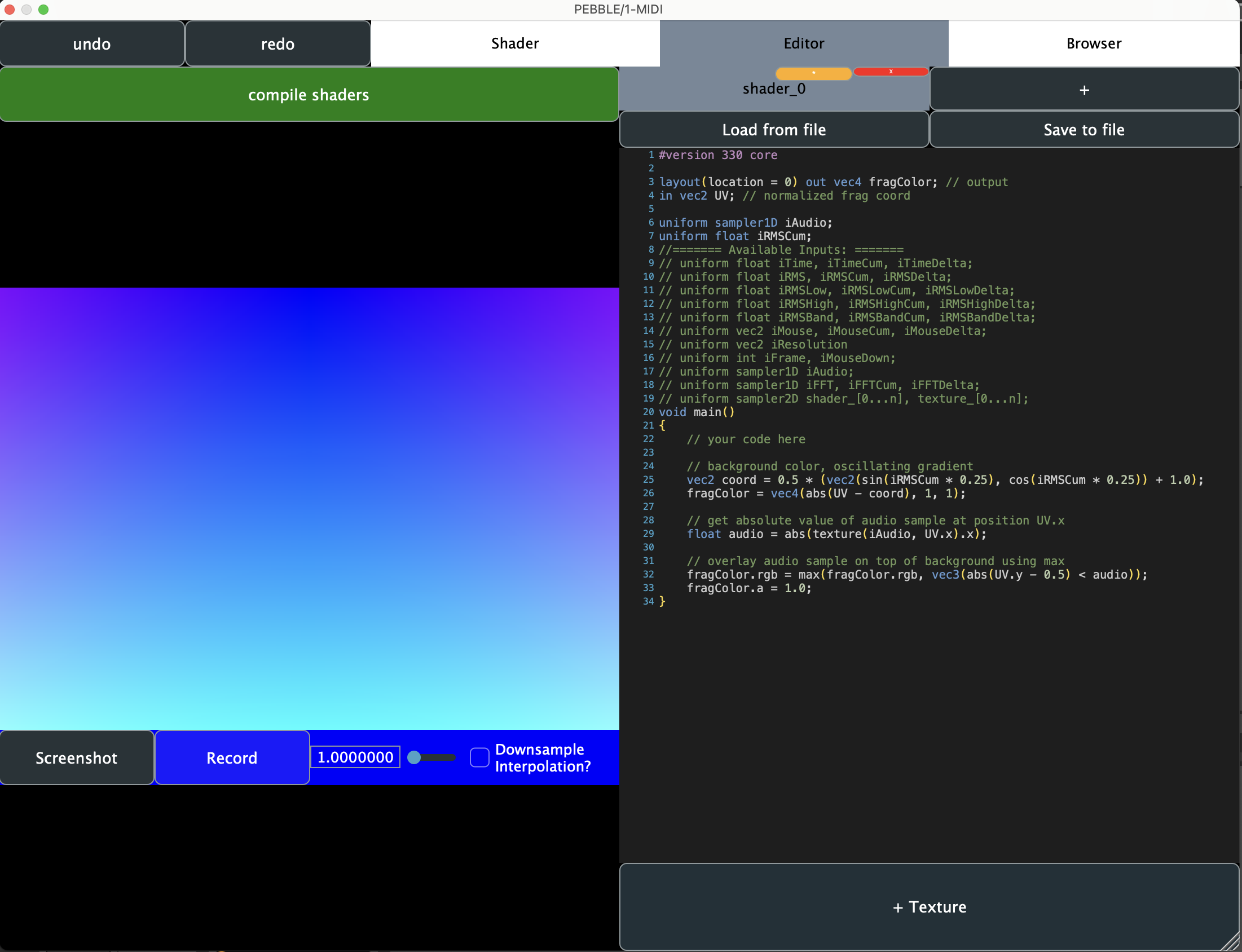
Pebble was created in collaboration with Jack Kilgore and has not been released publicly.
Pebble has three main tabs: the shader viewer, the shader editor, and the shader browser. The shader viewer displays the output of the shader across the entire plugin window. The shader editor allows users to write and edit shader programs in a text editor on the right side of the screen, while displaying the currently running shader on the left. The shader browser allows users to save and load shader programs and displays live previews of saved shader programs.
Users have access to set of pre-defined uniforms that can be used in their shaders. These include the current time, frame, mouse position, audio buffer, RMS amplitude of the audio buffer, and spectral view of the audio buffer. Furthermore, the user has access to a number of custom image texture uniforms and shader feedback/feedforward uniforms. Textures can be uploaded from a file by the user. The total number of shaders and the current shader being viewed are dynamic and defined by the user.
Pebble compiles shaders in real time. If there is a compilation error, an error message is displayed on the screen in lieu of the shader.
Users may screenshot and record their shader output for easy exporting. This is essential for sharing on social media.
Halo 3D Pan is a binaural panning plugin. It uses pre-recorded binaural impulse responses to simulate sound around a listener’s head in 3D space.

Halo 3D Pan has four main controls: azimuth, elevation, width, and focus. Azimuth controls the angle of the sound source around the listener’s head. Elevation controls the angle of the sound source above the listener’s head. Width controls amount of separation, in the azimuthal plane, between the stereo inputs of the sound sources. Focus fades between spatialized panning and traditional stereo panning.
Halo 3D Pan is intended for use by sound designers, soundtrack artists, game audio artists, and music producers who are looking to create an immersive listening experience that is tailored for headphones.
To spatialize audio input, Halo 3D Pan relies on head-related transfer function (HRTF) filters. These long FIR filters are implemented as convolutions with recorded impulse responses, typically captured using a real or dummy human head with a microphone in each ear. In my implementation, I use the spatialization filters from the “Spherical Far-Field HRIR Compilation of the Neumann KU100” HRTF dataset compiled by Benjamin Bernschütz [37]. In order to perform the convolution operation efficiently in realtime, Halo 3D Pan computes convolutions in the Fourier domain, taking advantage of the convolution theorem. I use the Pretty Fast Fast Fourier Transform (PFFFT) library to compute the discrete Fourier transform of incoming audio signals for this calculation [38]. Furthermore, I use an overlap add method with a 50% overlap to avoid aliasing at the FFT block boundaries. This method introduces a fixed latency to my plugin of half of an FFT block size (typically 64 samples).
The plugin features a unique raymarched 3D user interface, rendered in realtime on the GPU using a combination of three fragment shaders. The first shader computes hit-boxes for incoming mouse interactions. The second shader raymarches the 3D scene and computes the color of each pixel. The third shader applies post-processing to the 3D scene to create a glow effect. The user can click and drag on the 3D scene to change parameters of the plugin; when the user hovers over an interact-able element, a parameter description and value are displayed in the bottom left. The spectrum of the audio that is being processed is visualized atop the main knob.
The Template Plugin is a starting point for new JUCE plugin projects that builds on the best practices and creative solutions I have accumulated while working on the aforementioned four audio plugins. The main contribution of The Template Plugin is the ‘StateManager’ class, which provides an API (Application Programming Interface) for real-time safe interaction with the state of the plugin between threads. Furthermore, I include real-time safe interface sliders that interact with the StateManager via polling, I provide an example audio processing class which modulates the gain of an incoming signal, and I include instructions for expanding on the template.
The Template Plugin is on GitHub at github.com/ncblair/NTHN_TEMPLATE_PLUGIN. For instructions on installing The Template Plugin, see Appendix D: Installing The Template.
The Template Plugin enables easy creation and modification of plugin parameters. The typical process for creating parameters in JUCE is bulky and requires many lines of code for a single parameter. Consider the following block of code, which connects a single gain parameter to the host program.
std::vector<std::unique_ptr<juce::RangedAudioParameter>> params;
auto param_range = juce::NormalisableRange<float>(-60.0f, 6.0f, 0.0f, 1.0f);
auto param_suffix = "db";
auto param_default = 0.0f;
auto param_ID = "GAIN";
auto param_name = "Gain";
auto param = std::make_unique<juce::AudioParameterFloat>(
juce::ParameterID{param_ID, ProjectInfo::versionNumber}, // parameter ID
param_name, // parameter name
param_range, // range
param_default,// default value
"", // parameter label (description?)
juce::AudioProcessorParameter::Category::genericParameter,
[p_id](float value, int maximumStringLength) { // Float to String Precision 2 Digits
std::stringstream ss;
ss << std::fixed << std::setprecision(0) << value;
res = juce::String(ss.str());
return (res + " " + param_suffix).substring(0, maximumStringLength);
},
[p_id](juce::String text) {
text = text.upToFirstOccurrenceOf(" " + param_suffix, false, true);
return text.getFloatValue(); // Convert Back to Value
}
)
params.push_back(param);
apvts.reset(new juce::AudioProcessorValueTreeState(
*processor,
&undo_manager,
juce::Identifier("PARAMETERS"),
{params.begin(), params.end()}
));It’s inconvenient to type this code every time you want to add a new
plugin parameter. Instead, I set relevant parameter metadata in a .csv
file, parameters/parameters.csv. Adding a parameter becomes
as simple as defining the relevant information in a table.
| PARAMETER | MIN | MAX | GRAIN | EXP | DEFAULT | AUTOMATABLE | NAME | SUFFIX | TOOLTIP | TO_STRING_ARR |
|---|---|---|---|---|---|---|---|---|---|---|
| GAIN | -60 | 6 | 0 | 1 | 0 | 1 | Gain | db | The gain in decibels |
To convert between table data and JUCE parameters, a pre-build python
script reads the parameters.csv file and generates C++ code
that the StateManager class can use to create plugin parameters. This
code is exported to the file parameters/ParameterDefines.h
as a number of arrays of useful parameter information which can be
accessed by the rest of the codebase. Any code that imports
parameters/StateManager.h will also have access to the
definitions in ParameterDefines.h. The following code shows
how to access various attributes of a parameter from within the
codebase, using the PARAM enum:
#include "parameters/StateManager.h"
juce::Identifier parameter_ID = PARAMETER_IDS[PARAM::GAIN];
juce::String parameter_name = PARAMETER_NAMES[PARAM::GAIN];
juce::String display_name = PARAMETER_NICKNAMES[PARAM::GAIN];
juce::NormalisableRange<float> param_range = PARAMETER_RANGES[PARAM::GAIN];
float default_value = PARAMETER_DEFAULTS[PARAM::GAIN];
bool is_visible_to_host = PARAMETER_AUTOMATABLE[PARAM::GAIN];
juce::String parameter_suffix = PARAMETER_SUFFIXES[PARAM::GAIN];
juce::String tooltip = PARAMETER_TOOLTIPS[PARAM::GAIN];
// Given a parameter value, v, to_string_arr[v] is the string representation of the parameter value.
// to_string_arr can be used to implement drop down menus.
// if to_string_arr is not defined, the vector will be empty.
int v = int(state->param_value(PARAM::TYPE));
juce::String string_repr_of_param = PARAMETER_TO_STRING_ARRS[PARAM::TYPE][v];The StateManager class provides a number of real-time
safe ways to interact with the underlying parameters and state of the
plugin project. To access plugin state from any thread,
StateManager::param_value provides atomic load access to
plugin parameters. Furthermore, there are a number of
StateManager methods that change the underlying state of
the plugin from the message thread, including
StateManager::set_parameter,
StateManager::reset_parameter, and
StateManager::randomize_parameter.
Managing plugin presets with the StateManager is simple.
For most plugins, StateManager can automatically handle
preset management with the StateManager::save_preset and
StateManager::load_preset methods. For more complicated
plugins with state that cannot be expressed as floating point
parameters, such as plugins with user-defined LFO curves, presets will
continue to work as long as all relevant data is stored in the
StateManager::state_tree ValueTree object
returned by StateManager::get_state. This will likely
require modifications in the StateManager::get_state
method.
For more information about accessing the parameters of the plugin,
reference the code and comments in
src/parameters/StateManager.h.
The audio callback in The Template Plugin can be found in the
PluginProcessor class, which is defined in the files
src/plugin/PluginProcessor.cpp and
src/plugin/PluginProcessor.h. The
PluginProcessor::processBlock is invoked once per audio
block by the host, and returns samples to the speaker. This function
takes in a buffer of audio samples and a buffer of midi messages and
fills the input buffer with the desired output samples.
By default, The Template Plugin code applies a gain parameter to the
audio buffer in the processBlock, shown below:
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
juce::ScopedNoDenormals noDenormals;
//...
//--------------------------------------------------------------------------------
// read in some parameter values here, if you want
// in this case, gain goes from 0 to 100 (see: ../parameters/parameters.csv)
// so we normalize it to 0 to 1
//--------------------------------------------------------------------------------
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
//--------------------------------------------------------------------------------
// process samples below. use the buffer argument that is passed in.
// for an audio effect, buffer is filled with input samples, and you should fill it with output samples
// for a synth, buffer is filled with zeros, and you should fill it with output samples
// see: https://docs.juce.com/master/classAudioBuffer.html
//--------------------------------------------------------------------------------
gain->setGain(requested_gain);
gain->process(buffer);
//--------------------------------------------------------------------------------
// you can use midiMessages to read midi if you need.
// since we are not using midi yet, we clear the buffer.
//--------------------------------------------------------------------------------
midiMessages.clear();
}For real-time safe access to plugin parameters from the process
block, invoke the StateManager::param_value method by
passing the enum of the desired parameter, as defined in
parameters/ParameterDefines.h and equivalently in
parameters/parameters.csv.
The gain parameter is applied to the audio buffer via the
Gain class, defined in src/audio/Gain.h. The
Gain class smooths the Gain parameter before
modulating the amplitude of the incoming signal to avoid clicks and pops
on sudden parameter changes:
void Gain::process(juce::AudioBuffer<float>& buffer) {
// IIR filter to smooth parameters between audio callbacks
float target_gain = gain * (1.0 - iir_gamma) + requested_gain * iir_gamma;
// Snap to target value if difference is small, avoiding denormals
if (std::abs(target_gain - requested_gain) < 0.0001)
target_gain = requested_gain;
// Linear interpolation to efficiently smooth parameters within the audio callback
buffer.applyGainRamp(0, buffer.getNumSamples(), gain, target_gain);
// update internal gain parameter according to IIR filter output
gain = target_gain;
}The Gain class can be used as a starting point for more
complicated digital signal processing algorithms. To implement audio
algorithms that require additional memory, all memory should be
allocated within the PluginProcessor constructor and
PluginProcessor::prepareToPlay methods. Audio processing
classes may be dynamically constructed within the
PluginProcessor::prepareToPlay method if access to the
plugin sample rate, block size, or number of output channels is
required. I use the std::unique_ptr object to dynamically
allocate audio objects in the PluginProcessor; as long as
memory is allocated in the constructor or prepareToPlay
method, allocation will occur before the audio callback is invoked and
thus be real-time safe.
The plugin user interface can be modified from the
src/plugin/PluginEditor.h and
src/plugin/PluginEditor.cpp files.
ParameterSlider objects can be wrapped in
std::unique_ptr objects so that it is not necessary to
include the ParameterSlider.h file from the
PluginEditor.h header file, reducing compilation time.
// PluginEditor.h, private:
private:
// A single slider
std::unique_ptr<ParameterSlider> gain_slider;
// a second slider
std::unique_ptr<ParameterSlider> parameter_2_slider;Then, sliders may be created and positioned in the
plugin/PluginEditor.cpp file. Use the
AudioPluginAudioProcessorEditor::timerCallback method to
poll for state changes and trigger UI repainting. Polling from the timer
callback enables efficient and real-time safe repainting from the
message thread.
// Add elements in the constructor
AudioPluginAudioProcessorEditor::AudioPluginAudioProcessorEditor (PluginProcessor& p)
: AudioProcessorEditor (&p), processorRef (p)
{
...
// add slider BEFORE setting size
gain_slider = std::make_unique<ParameterSlider>(state, PARAM::GAIN);
addAndMakeVisible(*gain_slider);
parameter_2_slider = std::make_unique<ParameterSlider>(state, PARAM::PARAM2);
addAndMakeVisible(*parameter_2_slider);
...
}
// Position elements in resized
void AudioPluginAudioProcessorEditor::resized()
{
// set the position of your components here
auto slider_size = proportionOfWidth(0.1f);
auto slider_1_x = proportionOfWidth(0.5f) - (slider_size / 2.0f);
auto slider_2_x = slider_1_x + slider_size;
auto slider_y = proportionOfHeight(0.5f) - (slider_size / 2.0f);
gain_slider->setBounds(slider_1_x, slider_y, slider_size, slider_size);
parameter_2_slider->setBounds(slider_2_x, slider_y, slider_size, slider_size);
}
// Trigger repaint calls on parameter changes in the TimerCallback
// Only repaint components relevant to that parameter's changes
void AudioPluginAudioProcessorEditor::timerCallback() {
...
// handle parameter values in the UI (repaint relevant components)
if (state->any_parameter_changed.exchange(false)) {
if (state->get_parameter_modified(PARAM::GAIN)) {
gain_slider->repaint();
}
if (state->get_parameter_modified(PARAM::PARAM2)) {
parameter_2_slider->repaint();
}
}
...`
}The Template Plugin is intended to simplify the process of writing efficient and real-time safe audio plugins, while still allowing for flexibility and customization. Developers can start from The Template Plugin when building their own plugin codebase, or simply take code snippets and borrow design patterns from the template.
While The Template Plugin provides a good foundation, there are many additional techniques that are necessary to create large, production-level plugins. In this section, I will justify my design of The Template Plugin and outline various procedures for building out more complex real-time audio applications.
The Template provides real-time safe methods for accessing and
modifying atomic floating-point plugin parameters. Accessing and
assigning value to atomic variables is guaranteed to succeed without
blocking and without a data race. In particular, atomics are implemented
without locks for all primitive data types, such as float,
int, and bool. This makes sharing access to
primitive data fairly simple.
For arbitrary data types, it is important to note that atomics are
not always implemented without locks. For example, the real-time safety
of std::atomic<std::complex128> is system dependent.
Furthermore, std::atomic<std::shared_ptr> is commonly
implemented with locks. To check whether a certain data type of atomic
is realtime safe on a particular system, one can call
std::atomic<T>::is_always_lock_free.
Synchronizing access to objects which cannot be stored in atomics is more complicated. Consider, for example, the task of displaying an audio spectrum on the user interface for visualization in an equalization (EQ) plugin. To accomplish this, audio buffers must be sent from the audio thread to the message thread in real time. Audio buffers, however, cannot be stored in an atomic variable.
Since the best way to share access to non-atomic data types will vary greatly between plugins, this type of synchronization is not built in to The Template Plugin. Instead, developers may add custom code on top of The Template for their particular use case.
In the case of streaming data from one thread to another, a common
solution is to use a lock-free FIFO (First In First Out) queue. This
data structure takes advantage of atomics to coordinate read and write
access to a shared queue structure across threads. JUCE’s
AbstractFifo encapsulates all of the logic needed to safely
implement a lock-free FIFO.
Here is another lock-free FIFO use-case: say you want to generate
audio using a machine learning algorithm in real-time on your GPU. GPU
processing requires hardware level communication that is not safe on the
audio thread. Instead, to generate audio on a background thread, push it
to a FIFO, and read from it at the appropriate rate in the audio
callback. To access this audio on the UI thread and audio thread at
once, the lock-free FIFO implementation must support multiple readers.
moodycamel::ConcurrentQueue
is a good option for multiple reader queues [39].
FIFOs are great for streaming data, but require potentially expensive copy operations on the real-time thread. Furthermore, it is difficult to avoid memory allocation and deallocation when sharing dynamically sized data using a FIFO. Consider the problem of loading an audio sample from disk in an audio sampler plugin? In this case, you just need to send a single buffer from a background thread to the audio thread. Rather than copying the audio into a queue, it would be preferable to just move ownership of the object to the audio thread in a thread safe way.
To transfer ownership of a buffer from the message thread to the audio thread, one might be inclined to share an atomic pointer variable between the threads. That is, the background thread could load data without interrupting the real-time process. Then, when all of the data is loaded, it can store the memory-address of the data in an atomic variable that is shared with the audio thread. Using this structure, the audio thread could read data from the buffer held by the atomic with the confidence that the message thread is done editing that object. However, a problem occurs when the atomic is overwritten, say in the case that user loads a new file: the program must deallocate the old data that it is no longer using. When the message thread overrides the pointer to the old buffer, the message thread cannot deallocate that buffer because the audio thread may still be using it. And, if the message thread replaces the atomic pointer to the old buffer before it is deallocated, the program will have no more references to the old buffer data and no ability to deallocate that data in the future. This is referred to as a memory leak, and can lead to an unwanted build-up of program memory.
One attempt to solve this problem is to use an atomic
std::shared_ptr instead of a raw pointer to the audio
buffer, as std::shared_ptr automatically deallocates itself
when all references to the pointer are lost. However, atomic
implementations of std::shared_ptr are not typically
lock-free, so this solution is not real-time safe.
So, one cannot naively use atomic pointers to send data between threads. Timur Doumler outlines solutions to this problem in his talk Thread synchronisation in real-time audio processing with RCU (Read-Copy-Update) [20]. One solution combines a try-lock on the audio thread with a spin-lock on the message thread. These locks rely entirely on atomic flags, so no mutexes are necessary on either thread. However, spin locks can be very inefficient as their default behavior is to waste CPU cycles while waiting. To implement a more efficient spin lock, it is possible to use progressive back-off. Rather than constantly checking the lock, progressive back-off spin locks only check the lock a few times before waiting and eventually yielding for longer and longer periods of time. Note that since the spin-lock is on the message thread, it is okay for the program to wait if it doesn’t capture the lock immediately.
Here is a sketch of transferring data across threads using a spin lock. On the audio thread, use a non-blocking try-lock to attempt to read the data. On the message thread, use a non-blocking spin-lock to prevent the audio thread from reading the array when it is being updated. The following code borrows heavily from Timur Doumler’s blog [40].
struct SpinOnWrite {
std::atomic_flag flag = ATOMIC_FLAG_INIT;
void acquire_lock() {
// acquire lock via spinning
while (!try_lock()) {
// spin using progressive backoff
}
}
bool try_lock() {
return !flag.test_and_set(std::memory_order_acquire)
}
void unlock() {
flag.clear(std::memory_order_release);
}
}
// AUDIO THREAD
class AudioProcess {
SpinOnWrite lock;
std::shared_ptr<Object> data;
void readData(...) {
// try-lock
if (lock.try_lock()) {
// read data
}
// unlock
lock.unlock();
// if the lock was not successfully captured, use previous data
}
}
// MESSAGE THREAD
class InterfaceProcess {
AudioProcess& audio_ref;
std::shared_ptr<Object> data;
void modifyData(...) {
// spin lock
audio_ref.lock.acquire_lock();
// lock is always eventually acquired
// Modify data here
// unlock
audio_ref.lock.unlock();
}
}If you need to guarantee up-to-date data 100% of the time, it may be preferable to use a read-copy-update (RCU) style mechanism for thread synchronization instead of a spin-on-write system. RCU objects should have the following properties:
RCU objects are a good option when there are infrequent writes, such as in the case of loading a file for playback in a sampler.
For an open source and liberally licensed implementation of RCU as well as progressive backoff spin locks, see the real-time library Crill [5].
Real-time safe code does not guarantee efficiency, and inefficient code leads to high energy use and glitches on older, slower machines. While The Template Plugin comes packaged with efficient code, additional customization may result in a significant slow down. It is essential to consider optimization when writing audio plugins.
Writing fast code is a tradeoff. Efficient code is often necessarily low-level, which is harder to maintain. This makes sense, as higher level abstractions can add unnecessary overhead and prevent the compiler from fully optimizing.
To write code that is both maintainable and fast, it is critical to identify which sections of code benefit from aggressive optimization and which sections do not. For example, anything in the audio callback needs to be efficient to prevent audio glitches. The message thread, on the other hand, has a lot more flexibility – a single dropped frame every once in a while will not greatly diminish the quality of a user interface. Still, frequent dropped frames lead to a frustrating user experience. Always consider the opportunity cost of optimization: a small increase in performance is often not worth a large increase in the size of a codebase.
The first step towards speeding up a codebase is finding bottlenecks: the code that takes up the most processing time. Optimization before finding bottlenecks is rarely worthwhile; premature optimization often leads to negligible performance gains and decreased readability. It can be useful to have a fully working product before any optimization.
Applying optimization surgically to bottlenecks is the best way to end up with both high maintainability and high performance.
What is the best way to find bottlenecks? The most reliable way to find pieces of code with problematic performance is to profile, or measure the CPU and memory usage of a running program. One can manually write code to time performance or use one of many external profiling tools.
The MacOS application Instruments has a CPU profiler which
displays the CPU usage of individual function calls. Sorting by CPU
usage makes bottlenecks immediately pop out. Instruments relies
on debug symbols to identify functions, so it is best to build plugins
in RelWithDebInfo mode when profiling with
Instruments. This mode reveals debug symbols to the profiler
without altering the performance of the program. It is also possible to
profile Debug builds, but this will not provide an accurate
picture of performance in Release mode.
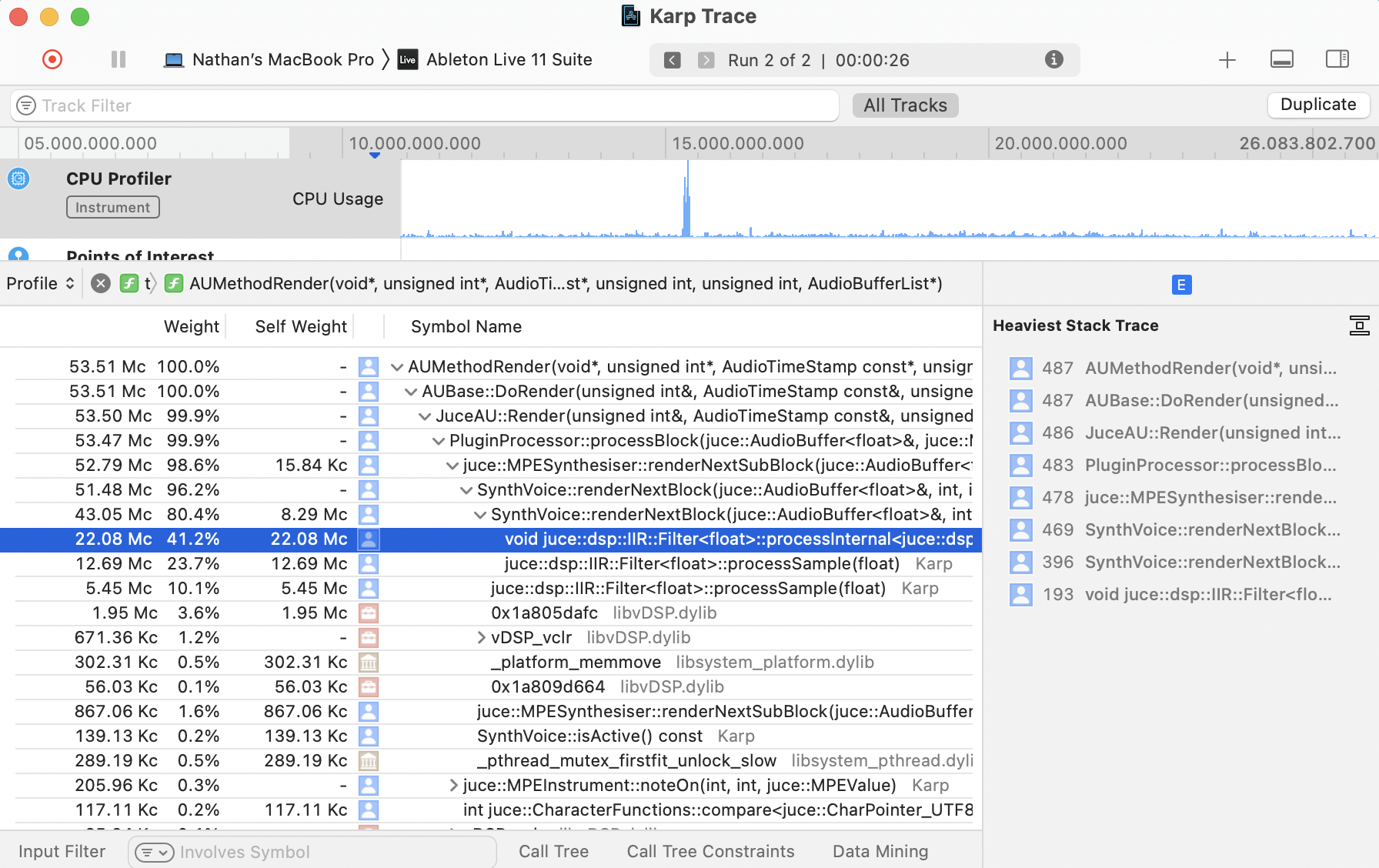
On Windows, a simple profiling tool is Very Sleepy by Richard Mitton [41]. Very Sleepy provides a similar call graph to Instruments.
Beyond knowing which functions are using the most CPU on average, it is useful to see a graph of when and for how long certain critical functions are being called. Perfetto is a profiling tool for C++ applications that displays a timeline of function calls on an interactive webpage. Furthermore, Perfetto can query worst-case runtime rather than only displaying aggregated information. This is essential in an audio context, as single glitches can cause performance drops. Melatonin Perfetto, created by Sudara, is a plug-and-play JUCE module for generating Perfetto trace files that is easy to integrate with JUCE projects via CMake [42]. The resulting trace files can be dragged into the Perfetto website and viewed in browser.
Most of the time, I prefer to profile with Melatonin Perfetto over Instruments. Being able to visually see when functions are being called too many times, for longer than expected, or with high runtime variance has pointed me in the direction of many successful optimizations.
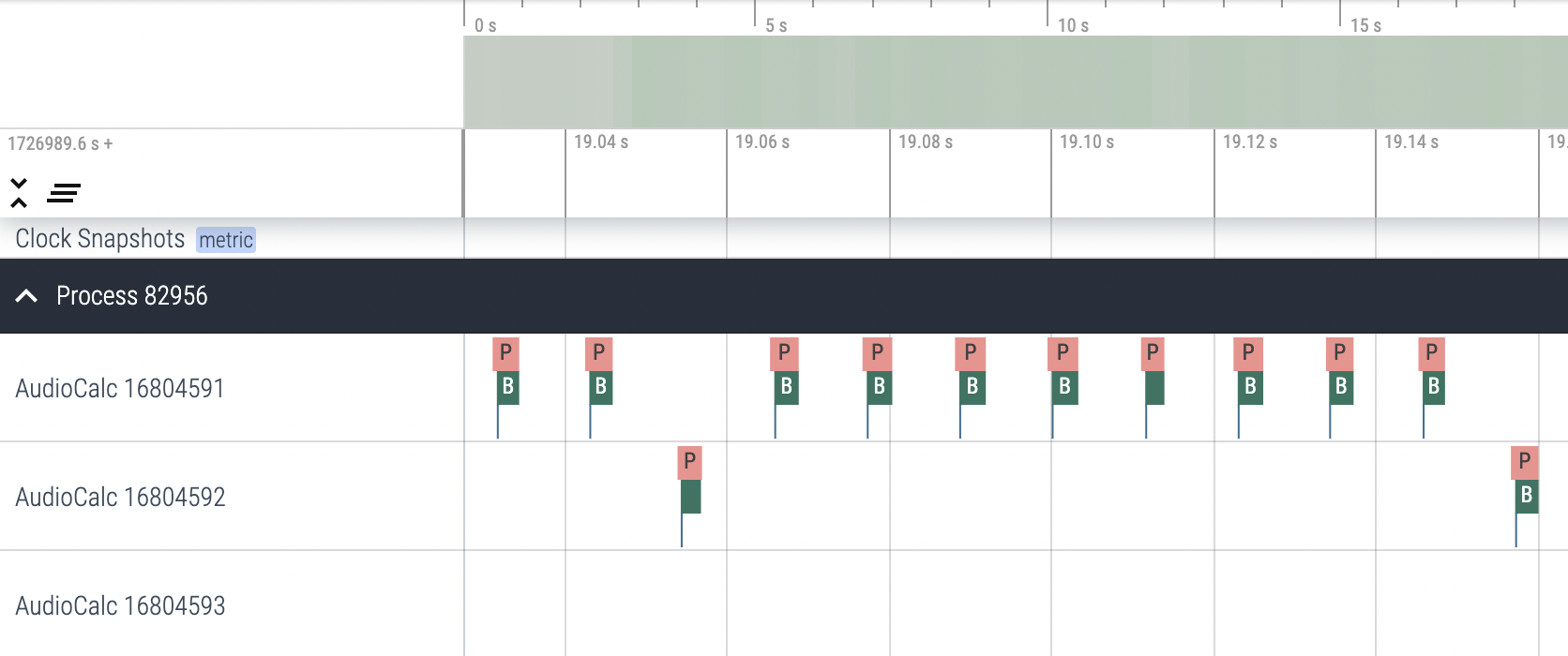
In some situations, I want more control over my profiling than Melatonin Perfetto offers. For example, I may want to compare multiple implementations of an algorithm, plot my performance in a unique way, or run my algorithm on specific worst-case inputs. In these instances, the best strategy is to manually write tests to benchmark performance. This is the most general and precise strategy, though it is also the most time consuming.
I will discuss real-time safe strategies for speeding up audio plugin bottlenecks. These strategies are most effective when applied after profiling, and depend greatly on the type of code being optimized.
The time complexity of an algorithm refers to the maximum number of operations required to compute the algorithm as a function of the size of the input. Typically, time complexity for an input of size \(n\) is expressed in Big-O notation: \(O(n)\), \(O(n^2)\), \(O(n^a)\), \(O(n\log n)\), etc.; the value within the parenthesis refers to the asymptotic behavior of the runtime rather than the exact number of iterations that it takes to compute. That is, constant factors and smaller terms are thrown away.
Decreasing time complexity via a faster algorithm is often the most valuable way to optimize code. As a heuristic, any audio block code that runs in time quadratic to the input buffer size is typically too slow. Even linear algorithms can be slow over large inputs in the audio callback.
One particularly important algorithm for speeding up audio algorithms is the Fast Fourier Transform (FFT), an efficient algorithm for computing the Discrete Fourier Transform (DFT) of a signal. The FFT can compute the DFT in \(O(n\log n)\) time – a significant speedup compared to the naive \(O(n^2)\) algorithm. There are many efficient open source implementations of the FFT – FFTW, PFFFT, juce::dsp::FFT, etc. – each of which have advantages and disadvantages but are all sufficient for use in the audio thread [38], [43].
It is useful to keep properties of the Fourier transform in mind when considering the algorithmic complexity of audio algorithms. In particular, sliding window operations, or convolutions, can be efficiently computed using the FFT as a subroutine. For large sliding windows, perhaps in a convolution reverb or spatialization plugin, FFT convolution is faster than naive convolution.
Another technique that is worth mentioning is the use of lookup tables for caching function output. In my own code, I commonly precompute values and store them in lookup tables to be accessed in the audio callback. For example, I use a lookup table in Karp for determining the delay length to use given a requested damping and pitch. Some care is required with this technique, however. Memory lookups tend to be much slower than floating point operations, and may also hurt cache performance. Furthermore, look-up tables implemented with hash maps may not be real-time safe. Hash map lookups typically run in amortized \(\Theta (1)\) time, meaning that they are constant time on average. In the worst case, however, hash maps can be prohibitively slow for the real-time thread.
On modern CPUs, it is possible to read data from the lowest level of memory storage, called registers, in a single clock cycle. This is not the case for a typical memory lookup, though. Main memory lookups can take hundreds of cycles, and reading from a solid state drive can take tens of thousands. Since registers are expensive, there are only a few registers per processor; most of the data in a program is stored in the main memory.

Between the registers and the main memory are the caches, which strike a balance between cost and speed. Commonly, caches are labeled L1, L2, and L3 in order of decreasing speed and increasing size. Accessing data in the L1 cache only takes a few CPU cycles – almost as good as reading directly from a register, while accessing L2 takes around 4 times as long [44]. Because of this, a program will always search first for data in the L1 cache, then to L2, then to L3, and finally to main memory. When the CPU cannot find some data in any of the caches, that is referred to as a cache miss.
Because of the high variance in memory lookup speed, the pattern with which a program accesses memory has dramatic runtime implications. Programs that use a small amount of memory, which can fit inside of the L1 and L2 caches, will be much more efficient than programs that often reference main memory.
To write cache friendly code, which minimizes cache misses, it is important to understand the principle locality. The principle of locality refers to the tendency of processors to access similar memory locations repeatedly over a short period of time. Programs tend to exhibit temporal locality, accessing the same data many times over a short time period, and spatial locality, accessing nearby data in memory over a short time period.

Modern CPUs take advantage of spatial locality by bringing data into the cache in chunks, rather than one byte at a time. When accessing an array in C++, a single element will be brought into the cache along with many nearby elements of the array. On my computer – a 2021 MacBook Pro – 128 bytes of data are loaded into the cache for each memory lookup. As such, 128 bytes is the cache line size of my CPU. This is equivalent to 32 floats with 32 bit precision.
This does not mean that my CPU always reads 128 bytes starting from the element I accessed. Instead, memory is partitioned into fixed cache lines; the processor will read the entire line that contains the requested value. Aligning data with the cache lines can provide additional speed benefits and simplify code.
Spatial locality is extremely useful in audio programming. Consider the case of reading an audio buffer during the audio callback. When traversing through the audio buffer, which is stored contiguously in memory, in order, the program needs only to reference main memory once every 32 samples. This reduces the computational cost of memory lookups by 10-20x.
Cache friendly code references data in the same order in which it is stored, as much as possible. Consider a 2D array stored in row-major order, that is, one row at a time back-to-back in memory. Traversing this array in column-major order will result in consistent cache misses because the processor will cache data from rows instead of the columns which are being read. Thus, it is important to be aware of the order in which memory is accessed. If an array must be traversed in column-major order, consider storing it in column-major order as well. Cache-friendly code may lead to an order-of-magnitude speedup.
Vectorization is a method doing multiple operations in parallel to increase efficiency. Rather than creating parallel processes running on separate CPUs however, vectorization takes advantages of special CPU instructions that run instructions on many pieces of data at once. These special instructions are referred to as Single Instruction Multiple Data (SIMD) instructions. SIMD instructions take advantage of locality by operating on small chunks of contiguous data at once, and do not require any system calls or otherwise non-realtime safe code. Vectorized algorithms are often just under 4x faster than non-vectorized code, but this depends on the type of problem and the CPU architecture.
Not all algorithms are good candidates for vectorization. Consider the following pseudocode, which applies a gain of 0.5 to an input signal:
for (int t = 0; t < num_samples; ++t)
output[t] = input[t] * 0.5;This code is easy to vectorize, as each output sample is independent. The output at each step is a simple function of the variable t. We can easily transform this to the following vectorized pseudocode:
for (int t = 0; t < num_samples / 4; ++t)
output[4 * t] = input[4 * t] * 0.5;
output[4 * t + 1] = input[4 * t + 1] * 0.5;
output[4 * t + 2] = input[4 * t + 2] * 0.5;
output[4 * t + 3] = input[4 * t + 3] * 0.5;While we have reduced the number of iterations in the loop by four times, we also need to do four operations per loop. We can resolve this by replacing the four calls to multiply and assign with a single SIMD call to multiply and assign:
for (int t = 0; t < num_samples / 4; ++t)
SIMD_ASSIGN(output[4 * t], SIMD_MUL(input[4 * t], 0.5));Compare this with the following pseudocode, which performs a low pass filter on the incoming signal:
for (int t = 0; t < num_samples; ++t)
output[t] = input[t] * 0.1 + output[t - 1] * 0.9;This code is much more difficult to vectorize, as the output values at each time-step are no longer independent. That is, the output at time-step \(t\) depends on the output at time-step \(t-1\). So, we cannot compute multiple values of the output in parallel.
SIMD instructions are architecture dependent. MacOS, Windows, and other platforms all require different SIMD code. Fortunately, JUCE provides a light wrapper for SIMD functions, so it is not necessary to write the same code multiple times.
JUCE’s SIMD implementation relies on the
dsp::SIMDRegister<T> struct. To write vectorized code
in JUCE, data must be wrapped in dsp::SIMDRegister<T>
before SIMD operations are performed.
Writing the gain example from above using JUCE’s SIMD implementation would look like this:
def apply_gain(float* input, float* output, num_samples) {
int step = juce::dsp::SIMDRegister<float>::SIMDNumElements();
for (int t = 0; t < num_samples / step; t++) {
index = 4 * t;
input = juce::dsp::SIMDRegister<float>::fromRawArray(input + index);
gain_applied = input * 0.5; // SIMD multiply operation is overloaded
gain_applied.copyToRawArray(output + index);
}
}There are a few additional caveats to consider when vectorizing code. First of all, SIMD vectorization only works on aligned memory. Memory is chunked not only by the cache line size, but also by the size of SIMD operations. For my machine, memory is grouped at every 128 bits, or four floats. For SIMD operations to work properly, the system assumes that the values being acted on take up the entirety of a single chunk of memory. When this condition is satisfied, we say that the data is memory-aligned.

The simplest way to create a memory aligned array is to allocate an array with extra space and then get a pointer to the first aligned index. Consider the following code for allocating a memory aligned array using JUCE’s SIMD implementation.
const int ARRAY_LENGTH = 32;
const int SIMD_SIZE = juce::dsp::SIMDRegister<float>::SIMDNumElements();
float* arr = new float[ARRAY_LENGTH + SIMD_SIZE]; // pad
float* aligned_arr = juce::dsp::SIMDRegister<float>::getNextSIMDAlignedPtr(arr);
...
// later when you want to delete the aligned array
delete[] arr;Finally, for SIMD to work, it is important that the total number of samples processed is a multiple of the number of samples that can fit inside a SIMD register. Otherwise, additional code is required to handle edge cases before applying SIMD vectorization.
Modern C++ compilers may be smart enough to vectorize some code without manual SIMD invocation. Tools such as Matt Godbolt’s Compiler Explorer can be used to determine if the assembly code generated by the compiler is already being vectorized [45]. In this case, writing SIMD manually is not necessary.
SIMD vectorization also tends to make code difficult to read and maintain; typical SIMD code adds manual memory alignment, awkward edge cases, and overall length to project files. As such, SIMD vectorization should only be applied to critical bottlenecks within a codebase.
Before I vectorize any code I make sure that (1) that code is a significant bottleneck, (2) that code is possible to vectorize, and (3) that code is not already being vectorized by the compiler. If these three conditions are satisfied, I feel justified in claiming the 4x speedup that SIMD enables. Waveshine relies heavily on vectorization. Furthermore, Halo 3D Pan uses a vectorized implementation of the FFT as a subroutine.
Loop unrolling is a technique for speeding up code by reducing
branching. Branching instructions change the order in which
code is executed, reducing the compilers ability to perform
optimizations. Common examples of branching are if
statements and for loops. In the most extreme case, loop
unrolling replaces loops with many individual lines of code executed
serially.
for (int i = 0; i < 4; ++i) {
std::cout << i << std::endl;
}becomes
std::cout << 0 << std::endl;
std::cout << 1 << std::endl;
std::cout << 2 << std::endl;
std::cout << 3 << std::endl;The second code block is potentially more efficient because it does not include any branching statements. Often, loops are partially unrolled. Consider the following code:
for (int i = 0; i < 2; ++i) {
std::cout << i * 2 << std::endl;
std::cout << i * 2 + 1 << std::endl;
}This partially unrolled version of the previous code executes two lines of code at a time and requires half the number of branches.
Like vectorization, loop unrolling is often done automatically by the compiler. Furthermore, loop unrolling greatly increases the length and decreases the maintainability of a codebase. Most of the time, I do not pursue loop unrolling. Still, it is a useful tool to have in rare situations where extreme efficiency is required.
Accessing specialized hardware within audio plugins is challenging. Since system calls are not real-time safe and audio plugins are developed for a diverse set of machines with different hardware capabilities, it is seldom worthwhile to move audio data onto a separate hardware device for processing. However, with carefully consideration of thread-safety and real-time safety, rendering audio on the GPU is an enticing option. The GPU takes vectorization and pushes it to the extreme, enabling hundreds of parallel operations at the same time. Applications of GPU audio include real-time audio synthesis using machine learning, parallel DSP running hundreds of filters at a time, and more.
Beyond GPUs, most modern computers come with digital signal processors (DSPs). These specialized hardware components are made for rendering audio, but are typically inaccessible to all but factory programs. Hopefully DSPs will become available to user programs in the future.
On the message thread, the GPU becomes a powerful tool for generating graphics. I use OpenGL in each of my plugins to render graphics efficiently on the GPU. Since the message thread does not have the same strict real-time safety requirements as the audio thread, GPU code becomes a much more attractive option.
In C++, certain floating point operations are faster than others. For example, division is significantly slower than multiplication and addition. Furthermore, transcendental functions such as sine and the exponential function require many other floating point operations as subroutines. There are, however, many approximate algorithms for speeding up the computation of slow math functions – consider using approximations for trigonometric functions, logarithmic functions, and square roots if exact values are not required.
When performing computations that can be evaluated at compile time,
significant speed-ups can be achieved by marking functions with the C++
keyword constexpr. This specifier notifies the compiler
that the function can be computed at compile time and will prevent the
program from doing unnecessary work at run time. Furthermore, code that
can be run at compile time has the additional benefit of being easier to
debug; compilers catch bugs in constant expressions immediately at
compile time, removing the danger of run-time failures.
Managing the state of an audio plugin is fundamentally about communicating information between threads. User interactions on the message thread must alter data in memory that is accessible from the audio thread. Given the challenges of synchronizing data across threads in a real-time application, it is no surprise that managing state is one of the most subtly difficult parts of writing a reliable plugin.
Discussing plugin state management requires a few key definitions.
AudioProcessor. Parameters are exposed
to and can be controlled by the host. Parameters are the main interface
between the host application and the plugin.JUCE provides a few classes for managing plugin state and parameters. It is not absolutely necessary to use these classes, but I find them useful in my own code.
The juce::ValueTree class provides a convenient tree
structure to “hold free-form data” [46]. ValueTrees are lightweight
references to a shared underlying data container, so they can be safely
copied around a codebase. ValueTrees provide a convenient
juce::ValueTree::createXml() method which makes them easy
to serialize to XML. Furthermore, many trees can be easily joined as
children under a parent tree. If one tree manages parameters and another
tree manages properties, a parent tree can contain information about the
entire state of the plugin. For these reasons, I use
juce::ValueTree in The Template Plugin to save and load
plugin state.
The juce::AudioProcessorValueTreeState (APVTS) class
manages audio parameters and handles interaction between those
parameters and the host. The APVTS has a juce::ValueTree
member variable, which contains the plugin parameters, and a set of
atomic variables for safely accessing those parameters from the audio
thread. It is important to note that the APVTS does not inherit from
ValueTree.
Both the ValueTree and the
AudioProcessorValueTreeState are a bit unwieldly and
struggle with storing complex data. Furthermore, some of the JUCE code
for connecting the APVTS parameters to the user interface is not
real-time safe. In The Template Plugin, the StateManager
class contains an APVTS and a few ValueTrees which can be accessed
indirectly via StateManager methods.
There are many types of parameters in JUCE, including
bool, choice, and int parameters.
In practice, only float parameters are necessary. Every
other type of parameter can be expressed as a float parameter with a
custom range and StringFromValue function. For example, a
boolean parameter can be expressed as a float parameter with possible
values in \(\{0.0, 1.0\}\), where \(0.0\) maps to false and \(1.0\) maps to true.
float parameters in JUCE are constructed with the
following mandatory arguments:
juce::String or
juce::Identifier that refers to the parameter along with an
int for the current version of the plugin. The version
allows hosts to deal with updates which increase or decrease the number
of parameters.Parameters may be initialized with additional optional arguments including:
stringFromValue. A lambda function that converts the
parameter’s string representation into a parameter value.To make parameters visible to the host, it is sufficient to construct an AudioProcessorValueTreeState instance with a list of parameters.
I’ve found that it requires a tedious amount of code to construct or modify parameter objects. In The Template Plugin, I define parameters in a simple .csv file and run a python script which auto-generates the C++ code for creating those parameters in JUCE.

Parameters definitions are assumed to fixed when the plugin is loaded. Because of this, it is not recommended to dynamically create parameters. Instead, all parameters should be defined when the plugin is constructed. While it may be possible to create additional parameter objects in code, most hosts will not handle these cases, which may lead to unexpected behavior.
Parameter changes from the host can happen on either the message
thread or the audio thread. Consequently, interacting with JUCE
parameters is not reliably thread safe. Fortunately, JUCE provides a
solution for this with the
juce::AudioProcessorValueTreeState::getRawParameterValue
function. This function returns a std::atomic<float>*
that holds the value of a parameter that can be safely loaded from any
thread.
Typically, both the audio thread and the message thread must react to plugin parameter changes. One way to react to changing parameters is by using listeners. Listeners are special objects which execute a callback function immediately when parameters are changed. In JUCE, listener callbacks are invoked synchronously on the thread where the parameter change happened. For parameter changes on the audio thread, modifying the user interface becomes problematic, and vice versa. Attempting to use listeners that may be called from any thread may lead to data races that can cause runtime failures and crashes.
It is possible to implement listener callbacks in a thread safe way.
JUCE’s built in SliderParameterAttachment class, for
example, take advantage of asynchronous callbacks when triggered from
the wrong thread. Asynchronous callbacks are executed at an unspecified
time in the future from the correct thread. In JUCE, this is implemented
with the juce::AsyncUpdater class by calling
juce::AsyncUpdater::triggerAsyncUpdate. However, As I noted
discussing the real-time safety of library
code, triggerAsyncUpdate initiates an operating system
call which may block the audio thread. While this won’t crash the
program, it may lead to an audio glitch. Hence, it is best to avoid
triggerAsyncUpdate as well.
Fortunately, there is a simple solution for accessing state that does not involve listeners: polling. To implement polling, check the atomic value of parameters on a fast timer from both threads independently. This eliminates the need to worry about thread safety – to access data on the audio thread when a parameter changes, simply poll from the audio thread; likewise for the message thread. I rely on polling heavily in The Template Plugin for synchronizing sliders, audio algorithms, and underlying parameter values.
There are some downsides to polling, however. Notably, polling does not guarantee real-time access to parameter updates. Instead, parameter changes are available at the rate of the timer callback. A polling timer must sample parameters sufficiently fast to not miss parameter changes. And, a fast timer introduces additional computation. Polling many parameters can be computationally expensive, as it requires checking the value of each of parameters every time the timer is invoked to see if anything has changed. Still, these downsides are fairly minor given improved real-time safety.
Polling parameter values will handle all parameter changes by the host. However, users can also interact with plugin parameters directly via the user interface. When the user clicks a slider or knob within the plugin interface, a listener callback is triggered. Instead of listening to parameter changes, however, this listener is triggered by mouse actions and is always called from the message thread. The simplest way to handle this type of interaction is to directly change the underlying parameter value associated with the slider. Once the parameter value changes, polling will take care of redrawing the slider and updating the audio thread. In other words, user interaction should not trigger any actions other than changing the underlying plugin parameters. The user interface and the audio will react to these changes in the same way that it reacts when the host changes a parameter.
How do parameter changes work in The Template Plugin? The Template Plugin is an audio effect plugin with a single parameter, gain, which modifies the volume of the incoming audio signal. The user interface of this plugin has a single slider that corresponds to the gain parameter.
In The Template Plugin, the audio thread needs an up to date value
for gain at each audio callback. To accomplish this, I poll at the
beginning of each call to PluginProcessor::processBlock.
Since processBlock is already called on a timer by the
host, no additional timer objects are necessary. To poll, I use the
StateManager::param_value method, which reads the value of
the parameter atomically using the
AudioProcessorValueTreeState::getRawParameterValue
method.
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
...
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
...
}On the message thread, interface sliders should be redrawn whenever parameters are changed. In The Template Plugin, I manually create a timer callback that requests a repaint of the slider every time the gain parameter changes. Furthermore, the up-to-date value of the gain parameter is read from the slider’s paint call.
void AudioPluginAudioProcessorEditor::timerCallback() {
...
// repaint UI and note that we have updated ui, if parameter values have changed
if (state->any_parameter_changed.exchange(false)) {
if (state->get_parameter_modified(PARAM::GAIN)) {
gain_slider->repaint();
}
}
...
}void ParameterSlider::paint(juce::Graphics& g) {
// keep up to date with the parameter via polling
auto cur_val = state->param_value(param_id);
auto normed_val = PARAMETER_RANGES[param_id].convertTo0to1(cur_val);
...
}Fast parameter changes can cause unwanted clicks and glitches in the audio output. Consider the following example.
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
...
auto gain = state->param_value(PARAM::GAIN) / 100.0f;
buffer.applyGain(gain);
}If the user changes the gain parameter from 0.0 to 1.0, the rapid change in audio amplitude will be perceived as an audible click. Even if the user requests a smooth transition in the parameter value, the audio callback may still record large step as parameter changes are only sampled once per audio block.
Often it is desirable to reduce clicks by smoothing out parameter changes. There are two common methods to achieve this: low pass filtering and linear interpolation. Both methods effectively smooth parameter changes – which method you choose depends on the desired behavior of your plugin.
When linearly interpolating between parameter values, there are two
options: fixed rate linear interpolation and fixed time linear
interpolation. Fixed rate linear interpolation sets a maximum rate of
change for each parameter value. This method reliably reduces unwanted
behavior caused by large parameter changes, but may result in slow,
unresponsive transitions between parameter values. On the other hand,
fixed time parameter value changes set the amount of time it takes to
transition to the next parameter value. This method is effective if
lengthy smoothing procedures are unwanted, but may be less effective at
reducing clicks in all cases. The juce::SmoothedValue class
implements fixed time linear interpolation. All smoothing methods
require at least one additional instance variable to store the smoothed
state of the parameter.
// FIXED RATE INTERPOLATION
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer, juce::MidiBuffer& midiMessages)
{
// poll gain parameter
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
// get difference between requested parameter and stored parameter
auto difference = requested_gain - gain;
// set max parameter change
auto max_parameter_change = 0.05;
if (difference < 0) {
max_parameter_change *= -1;
}
// limit parameter change to max_parameter change
gain += std::min(difference, max_parameter_change);
// apply smoothed gain param to audio
buffer.applyGain(gain);
}// FIXED TIME INTERPOLATION WITH juce::SmoothedValue
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
// poll gain parameter
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
// gain is a juce::SmoothedValue object
// update target value of smoothed value
gain.setTargetValue(requested_gain);
// apply smoothed gain param to audio
buffer.applyGain(gain.getNextValue());
}Another option is to use a low pass filter for interpolation. This option is easy to implement and results in smooth exponential curves between parameter values. However, low-pass-filtering parameters has drawbacks as well. Infinite impulse response (IIR) filters may never reach the requested parameter value, and can lead to small floating point numbers called denormals which can dramatically increase CPU load. Finite impulse response (FIR) filters fix this, with the downside of being less smooth and more computationally expensive. Furthermore, low-pass filtering does not guarantee a maximum parameter value change, so it is still possible for clicks to occur. Still, the small amount of code needed to implement low-pass filtering makes it an attractive option in a pinch.
// IIR Filter interpolation
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
// poll gain parameter
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
// IIR filter with filter parameter 0.03
gain = gain * 0.97 + requested_gain * 0.03;
// apply gain param to audio
buffer.applyGain(gain);
}// FIR Filter Interpolation
void PluginProcessor::processBlock (juce::AudioBuffer<float>& buffer,
juce::MidiBuffer& midiMessages)
{
// poll gain parameter
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
// FIR Filter interpolation (Moving Average)
auto gain = requested_gain * 0.5 + past_requested_gain * 0.5;
past_requested_gain = requested_gain;
// apply gain param to audio
buffer.applyGain(gain);
}In each of these examples, smoothing is applied at the block rate. For particularly sensitive algorithms, it may be necessary to smooth at the sample rate instead. In The Template Plugin, I use an IIR filter to smooth at the block rate, and a linear ramp across the buffer at the sample rate. I found this solution to be optimal as it avoids clicking even for large block sizes, while still being easy to implement and more efficient than performing IIR interpolation at the sample rate. Furthermore, careful computation of the IIR smoothing parameter makes the smoothing rate independent of the sample rate and block size, so the plugin will sound the same in different conditions.
// The Template Plugin Parameter Smoothing
void Gain::process(juce::AudioBuffer<float>& buffer) {
// poll gain parameter
auto requested_gain = state->param_value(PARAM::GAIN) / 100.0f;
// get IIR interpolated gain at the block rate
float target_gain = gain * (1.0 - iir_gamma) + requested_gain * iir_gamma;
// snap IIR interpolation to avoid denormals
if (std::abs(target_gain - requested_gain) < 0.001)
target_gain = requested_gain;
// Apply linear interpolation gain ramp to the IIR interpolated value
buffer.applyGainRamp(0, buffer.getNumSamples(), gain, target_gain);
gain = target_gain;
}
// Calculating the IIR Smoothing Parameter
Gain::Gain(float sample_rate, int samples_per_block, int num_channels, float init_gain) {
...
// set IIR filter s.t. we sample once per block and the filter cutoff is 1000hz
iir_gamma = 1.0f - std::exp(-2.0f * PI * 1000.0f * samples_per_block / sample_rate);
...
}Modulation is a deep topic with many possible implementations. I will
briefly discuss my approach to modulation before reiterating real-time
safety best practices in the context of user-defined modulators.
Modulation is not built in to the Template Plugin, but may be built on
top of the StateManager class.
Unlike parameter automation, modulation does not change the state of a plugin. Instead, modulation is a technique for changing the expression of plugin parameters over time. Common modulation sources, or modulators, include low frequency oscillators (LFOs), envelopes, and macro parameters. Consider a modulator signal given by \(m(t)\) and a time-varying parameter value \(p(t)\). Then, the modulated parameter signal, \(p\prime(t)\) can be expressed as \(p\prime(t) = p(t) + \alpha(t)*m(t)\), where \(\alpha(t)\) is the strength of the modulation over time.
\(p(t)\) and \(\alpha(t)\) are typically parameters which can be read directly from the plugin state. \(m(t)\), the modulator signal, may be read directly from the plugin state (in the case of a macro parameter) but is more often a function parameterized by some information in state (e.g. a low frequency oscillator (LFO)). \(p\prime(t)\) can be used to drive digital signal processing algorithms, but is not itself stored in state.
It is often desirable for users to draw the shape of modulation signals. This is one of the more challenging features to implement in a plugin.

Consider a drawable LFO, which is comprised of a set of \(n\) fixed points. Since LFO signals are periodic, the first fixed point determines the start value and the end value of the waveform. Users can add additional fixed points by double clicking the plugin window. We can store the \(n\) fixed points that define the LFO in an array of floats. Reading from this array while it is being modified is not thread safe, and using locks to read from the array is not real-time safe.
With a maximum number of fixed points, it is possible to store the LFO data as an array of atomic values which can be modified by both threads. In the case where users can add an arbitrary number of fixed points, real-time safe synchronization solutions such as RCU objects or real-time spin locks are required.
Most plugin hosts will automatically add parameter changes to their undo history. However, hosts do not track all state changes within the plugin. This means that only certain actions – those which modify parameters – will be automatically undo-able.
It is possible to manually add undo/redo functionality within a
plugin by using JUCE’s juce::UndoManager and
juce::ValueTree classes. Changes to value tree properties
may be accompanied by an UndoManager object which can undo
changes. Using the UndoManager is more flexible than
relying on the host, as it enables grouped actions and custom undo
actions. This is useful for undo-ing actions that dramatically change
the state of the plugin like changing presets.
However, having two separate undo histories – one in the plugin and one in the host – will inevitably lead to coordination issues. I haven’t found a perfect solution for undo/redo actions; in fact, many popular plugins that I use contain actions that are not undo-able.
Even though JUCE graphical user interfaces are rendered on the message thread, and are thus not subject to the strict real-time constraint of the audio thread, they must still be rendered efficiently enough so that the user does not experience significant latency or dropped frames. Designing efficient user interfaces in JUCE requires careful consideration of element hierarchy and screen painting logic. The Template Plugin is designed to minimize unnecessary processing when rendering the user interface.
The juce::Component class is the basic building block of
JUCE user interfaces. Components represent elements on the screen and
are organized in a hierarchical tree structure. That is, each component
can have many child components which are rendered within their parent.
When the parent is repainted, so are all of the children.
The juce::AudioProcessorEditor class is a component that
is automatically added to the plugin window and occupies the entire
window. All user interface elements will be lower in the component
hierarchy than the plugin editor. The AudioProcessorEditor
is visible by default.
For other interface components to be visible, they must be added to a
visible parent component, such as the PluginEditor.
Furthermore, they must be set as visible with setVisible.
Both of these can be accomplished simultaneously with
Component::addAndMakeVisible. Finally, components need to
be given a size to be visible, which is typically accomplished by
calling the Component::setBounds method from within the
parent component’s Component::resized callback.
Repainting in JUCE is complicated. Parent component paint calls
trigger child component paint calls. This is desirable: repainting a
parent component should paint all of the children that make up the
parent. What’s less desirable, though, is that child component repaint
calls may also trigger parent component repaint calls [47],
[48]. This means that a single repaint call on a
small component may cause a chain of reactions that results in the
entire plugin being redrawn. To make matters worse, many functions
implicitly trigger repaint calls – such as setVisible and
setBounds – and many JUCE built in components call
repaint frequently.
Each component has a paint callback that is invoked by
the operating system. In particular, the host application calls through
to juce::ComponentPeer::handlePaint which then triggers a
paint call in the actual component and is drawn on the screen.
paint calls begin with the top most component and are
triggered down the chain to all child components in order. First the
parent component paint is called, then all of the child
components paint are called, and so on recursively.
Usually, we only need to repaint a small section of the screen, like
a single small knob. To let the operating system know which components
actually need to be repainted, we use the
Component::repaint method. Component::repaint
does not call the component paint method directly. Instead,
it marks that component as dirty. That information propagates up to the
top level ComponentPeer. Then, the operating system uses
information from the peer to repaint specific sections of the
screen.
By default, if a child component is marked dirty via
repaint, the parent component will typically also be marked
as dirty. This is because components are transparent by default. If you
repaint a transparent child component, you also need to repaint whatever
is underneath it – often the parent component – so that the operating
system can blend them together. If repaint calls start
propagating up the chain, the entire UI will need to be repainted for
every change. The solution is to mark components as opaque by calling
Component::setOpaque(true). Opaque components will not
trigger upstream repaint calls. When setting a component as
opaque, it is important to completely fill the component bounds in that
component’s paint function. Otherwise, artifacts resulting
from certain sections of the screen not being repainted may appear.
In The Template Plugin, user interface knobs are only marked for repainting when their associated parameter changes. Furthermore, Template Plugin knobs are marked as opaque so that paint calls do not propagate upwards.
A laggy, unresponsive user interface makes it extremely difficult to navigate a plugin; it is crucial to optimize plugin interfaces, and the first step in optimizing is profiling.
One of the best ways to get significant efficiency improvements on the UI is by reducing extraneous paint calls. This is done by setting components to opaque when possible, and removing unnecessary calls to repaint in the codebase.
Melatonin Perfetto allows one to “see how many times paint calls occur, what the timing is for each call, the timing of any child paint calls, etc” [23]. This immediately provides information about extraneous paint calls. If Perfetto is too much work to set up, printing to the console in the paint calls of relevant components may give enough information to debug.
Some complex animations and 3D user interfaces are too computationally intensive to render on the CPU in real-time. In these cases, hardware accelerated graphics can help. Rendering audio plugins on the GPU takes more work to set up, but also unlocks the potential for radically more dynamic user interfaces.
CPU bound plugin GUIs must be simple so that the CPU can focus on audio processing. Interfaces on the CPU use basic vector graphics, small PNGs, and modest animations. Anything more could lead to an unresponsive interface.
Instead of relying on the CPU, why not move computationally expensive GUI components on the GPU? GPU graphics can be incredibly complex while still running in realtime – no CPU power required.
Unfortunately, different hardware systems support different types of GPU code. For example, NVIDIA GPUs understand CUDA code, but Apple GPUs understand Metal. To write cross platform GPU code, it is often necessary to use a higher level framework that compiles for multiple platforms.
OpenGL is a cross-platform programming interface for hardware accelerated graphics. OpenGL runs on all major operating systems (MacOS, Windows and Linux) out of the box, making it a great choice for writing once and running anywhere. Furthermore, JUCE already has support for OpenGL-based components. This makes it relatively painless to set up compared to other hardware accelerated graphics frameworks.
Unfortunately, Apple deprecated OpenGL on MacOS in June 2018 in favor of Metal. While OpenGL code still runs on MacOS for now, it may not be supported in the future.
There are other options for cross platform hardware accelerated graphics frameworks, including BGFX and WebGPU. However, since these are not natively integrated with JUCE, they require a lot of set up. With ample time and resources, using one of these frameworks is optimal. Otherwise, OpenGL is still a good option.
GPU code tends to suffer from induced demand. With all of the extra processing power GPUs afford, it is tempting to design computationally expensive 3D graphics systems. Even on the GPU, there is a limit to how much computation is possible in real-time. This is exacerbated by the high variance in GPU performance between machines. The same code may run smooth on a gaming computer, but fail on an older laptop. Furthermore, slow GPU code may cause the entire display to lag, not just the plugin window. Thus, it is essential to test GPU code on slower and older machines. And, as always, profile GPU code to optimize performance.
I have used hardware accelerated graphics in some capacity for each of my plugins. Karp uses OpenGL to create dynamic 2D animations in the background of the plugin window. Waveshine uses OpenGL to create a dynamic feedback-based visualizer. Pebble allows users to write and compile their own GPU code from within the plugin, enabling dynamic audio visualizers. Halo 3D Pan uses raymarching, a lightweight 3D rendering technique, to create a fully real-time 3D rendered plugin interface. For more information on raymarching, see Appendix C: Raymarching UIs.
JUCE comes with a program called the Projucer for compiling JUCE projects. However, the Projucer adds a lot of bulk to the development process. Using the Projucer requires the use of heavy interactive development environments like Xcode or Visual Studio. I prefer not to open a bulky GUI every time I need to run my code.
Instead of the Projucer, I prefer to build my JUCE projects with CMake. This allows me to build crossplatform using whatever code editor I prefer. It also enables me to build my program from the command line or as part of a shell script that takes care of pre-build tasks.
For complete instructions for building The Template Plugin, see Appendix D: Installing The Template.
The Template Plugin comes with a build script, build.sh,
which accomplishes three tasks every time the plugin is recompiled.
Generating code: in The Template Plugin, parameters are defined
in a .csv file for rapid creation, editing, and deletion. Before
building, I run a python script which generates verbose C++ code based
on that .csv file. That C++ code is then compiled into the plugin. The
Template Plugin also uses code generation to create a
src/plugin/ProjectInfo.cpp file that exposes relevant
metadata such as the name and version of the plugin to the project. Code
generation is extremely flexible for transforming metadata and
hyper-parameters into verbose code and for precomputing complex
functions.
Compiling the plugin: The Template Plugin is built by running the
cmake command. If successful, this automatically adds the
compiled plugin to the plugins folder on my computer. I run the
following lines of code on MacOS to build:
cd build
cmake -DCMAKE_OSX_ARCHITECTURES="arm64;x86_64" -DCMAKE_BUILD_TYPE="$MODE" -DCMAKE_OSX_DEPLOYMENT_TARGET=10.10 ..
cd ..
cmake --build buildperipheral./Applications/Ableton\ Live\ 11\ Suite.app/Contents/MacOS/Live peripheral/Test\ Project/Test.alsSince I do each of these three steps every time I compile, it is convenient to initiate the entire process from a single script file. Using a script to build my code has made coding more efficient and enjoyable.
As far as I know, my proposed template, The Template Plugin, is the only JUCE template project that explicitly aims to enforce real-time safe design patterns. In particular, I emphasize polling over listener callbacks on both the audio and message threads, and provide a system of atomic values for interacting with plugin parameters and properties.
Furthermore, The Template Plugin provides a number of convenient methods for rapid plugin development that are not available in other templates. I include a simple .csv file for defining JUCE parameters, which along with a code-generation script, massively reduces the amount of code necessary to make parameters visible to a host application. Furthermore, The Template Plugin comes with an intuitive API for accessing and modifying plugin state, resulting in easily readable code.
The Gain class in The Template Plugin demonstrates a
simple, optimized audio processor class that developers can reference as
a starting point for more complex DSP classes. The
ParameterSlider class demonstrates thread and real-time
safe methods for interacting with plugin state as well as methods for
reducing extraneous repainting calls. The ParameterSlider
can be used as a starting point for more complex user interface
elements.
While The Template Plugin is intended to simplify the process of creating audio plugins, it may not be the best option for complete beginners. In particular, customizing The Template Plugin requires deep knowledge of C++ programming, digital signal processing, and design. Because of this, The Template Plugin is best suited for experienced C++ developers who are new to audio programming and JUCE developers looking to improve the reliability of their code.
Unlike Sudara Williams’ pamplejuce and Nicholas Berriochoa’s juce-template, The Template Plugin does not come with a framework for testing plugin code. Testing is an essential aspect of developing reliable software, and may need to be manually added on to The Template Plugin in professional development contexts.
Furthermore, The Template Plugin does not ship with code for synchronizing dynamically sized objects between threads. Instead, users of The Template Plugin must use third party or custom synchronization solutions, such as Crill.
There are many potential directions for expanding The Template Plugin.
Additional UI components such as audio visualizers, drawable parameter modulators, and file loaders would provide valuable examples of handling real-time safety and thread safety in more complex contexts than sharing floating point parameters.
Implementations of memory-intensive digital signal processing algorithms such as convolution-based filters, feedback delay networks, and sample-based synthesizers could be included in The Template Plugin as examples of how to avoid memory allocation on the audio thread and how to write optimized, cache-friendly code.
The inclusion of a testing framework would provide an additional tool for professional developers to improve the reliability of their plugins.
Examples of storing dynamically sized state using the
juce::ValueTree objects in the StateManager
class could help flatten the learning curve for implementing complex
plugins using The Template Plugin.
Starter code for developing hardware accelerated user-interfaces would save developers the tedious process of properly configuring OpenGL in JUCE. Furthermore, the inclusion of a framework for web-based interfaces would allow developers to take advantage of popular web frameworks that they may already be familiar with, such as react-js.
I introduced The Template Plugin, a template codebase for JUCE plugins which encourages best practices for real-time thread-safe programming. The Template Plugin is based on my experience developing four plugins in JUCE – Karp, Waveshine, Pebble, and Halo 3D Pan – each of which have contributed to my understanding of developing performant and reliable audio plugins. I have justified my design of The Template Plugin with an in-depth discussion of thread synchronization, optimization, state management, user interface design, and build systems within the context of audio plugins. I hope that this document, along with The Template Plugin, will enable audio researchers to release their algorithms as plugins to the international community of music producers, sound designers, and audio engineers.
Software is copyable; there is very little preventing someone from purchasing a software product once and distributing it for free to everyone else. Even in the context of non-commercial plugins, it may be desirable to track downloads and collect user contact information. This is only possible if those users download the software through official sources.
To prevent unwanted copying and distribution, developers tend to include some form of copy protection in their code. Copy protection often involves distributing unique licenses to each authorized user of a software with which they can confirm their identity. Copy protection falls under the larger umbrella of data rights management (DRM): any management of legal access to digital content.
Intentionally circumventing copy protection is referred to as cracking software. Cracked software is everywhere in the audio plugin industry – a quick google search of “cracked audio plugin” provides easy access to websites where users can download unofficial versions of popular plugins. Some anecdotes have only 3% of plugin users as legal owners of the software [49]. In an unofficial poll of 373 producers on this audio forum, every single respondent reported using cracked plugins at least some of the time [50]. While I do not have official data on the percentage of audio software that is pirated, my own experience as a music producer and a software developer suggests to me that the majority of plugins in use today are cracked.
The truth is that there is no 100% reliable way to prevent bad actors from cracking software (unless, perhaps, you have a quantum computer [51], [52]). With enough time, a sophisticated hacker will be able to reverse engineer any plugin and create a version that is trivially copyable to anyone else’s machine, for free. Thus, the goal of any good data rights management scheme should be to make the process of cracking sufficiently frustrating and time-consuming for the hacker. For a smaller plugin company, with a less popular or cheaper plugin, making software that takes a long time to crack is often enough to disuade bad actors.
At the same time, interacting with complex data rights management schemes can be frustrating on the developers end. It takes a lot of time and a decent understanding of cryptography to implement copy protection correctly. For a single developer or a small team, it might not be worth the hassle. Adding copy protection may also add unwanted friction to at the user-end; authorized users certainly shouldn’t have to struggle to get past copy protection code.
There is some controversy over whether using cracked software is ethical. Many argue that cracking software is a victimless crime, or that all software should be free under freedom of information. For developers who believe this, it may be worth releasing plugins open source under a free software license such as GPLv3. As an added benefit, this will greatly simplify the distribution process, as I will discuss in Appendix B: Distribution. Personally, I do not make a value judgement either way when it comes to cracking – still, I choose to include copy protection as a practical matter in an attempt to increase my profits and gain a better understanding of who is using my software.
For those who know that they want copy protection, but don’t want to implement it themselves, there is a third option: hiring a company like PACE to handle data rights management. There are some notable downsides to this approach, however. While these companies may have advanced DRM schemes, they may also be high priority targets for hackers. Furthermore, contracting DRM to a third party may be prohibitively expensive.
There are two main types of attacks that hackers use to bypass license verification based copy protection schemes. Key generators (keygens) are programs that exploit unsecured crypto-systems to generate fake licenses that will pass verification checks. Cracks are modified software that no longer contain or otherwise bypass verification checks. It is impossible to completely prevent cracks. However, it is possible to prevent keygens. Preventing key generators should be the goal of all but the bare-minimum copy protection schemes. Cracks, on the other hand, are difficult or impossible to completely prevent. In the best case, developers can make their plugin binaries extremely resistant to reverse engineering and cracking.
This section comes with a disclaimer: I am not a cryptography expert. Furthermore, RSA is not the only way to implement data rights management. That being said, here is one way to go about implementing a cryptographically secure data rights management scheme using the RSA crypto-system.
RSA, named after it’s creators Rivest, Shamir and Adleman, is a public-key crypto-system commonly used for sending encrypted messages over open channels. I will spare the actual implementation details of RSA - while they are interesting, it is not necessary to understand the RSA algorithm to implement an RSA scheme. Instead of implementing RSA, it is best to use a third party library for key generation, encryption, and decryption. Popular third party libraries will be less likely to contain errors that can be exploited by bad actors – just be careful about calling any third party code from the audio thread, as always.
In our case, we want to communicate between our plugin and a private web server which is able to validate licensed users. In particular, our server should be able to send an encrypted message to the plugin that determines whether a user is licensed. Importantly, only the server should be able to generate a message that passes the plugin’s check. Furthermore, that message should be specific to the particular machine the user is on; reading the message from another computer should not pass the plugin’s checks.
Here’s how it works.
Good news: RSA is cryptographically secure. As long as a hacker is not able to alter the plugin binary, they will not be able to activate the plugin. Keygens can not get past RSA.
Bad news: hackers are able to make changes to the plugin binary. Implemented naively, RSA encryption is only marginally better than no copy protection at all.
Consider the following code:
bool is_licensed = correct_RSA_scheme_check();
if (is_licensed) {
// do processing
}
else {
// fail
}This code has a single point of failure. No matter how complex it is
to break the RSA scheme, if a hacker can replace the
is_licensed variable with true, the program
will always run normally whether it is licensed or not.
Any data rights management scheme will encourage good-faith users to purchase plugins directly. However, for those who are concerned with preventing cracks, there are a few things to do beyond using a cryptographically secure DRM scheme. This section references Chase Kanipe’s talk “Tips From a Hacker on License Checking” at The Audio Developers Conference, 2022 [53].
Diffusion: license verification checks should be spread across the codebase, and should occur at different points in time. There should be no single line of code that a hacker could change to crack the plugin. Consider including checks that happen a long time after the plugin loads, or a certain amount of time after it is downloaded.
Obfuscation: it should be difficult for a hacker to understand what is going on in the code. Debug symbols should be left out of the binary. Sensitive data like public keys should be encrypted at compile time. Consider including fake license verification checks to throw off the hacker.
Integrity: include checks that ensure that the code has not been altered. This can range from checking the hash value of certain critical bytes in the binary to simply checking that bad license files do not pass the checker at runtime.
Variety: Add many different types of checks in the code. If each license verification check uses the same underlying pattern, they may be searchable and easily identified. To get around this, use a different algorithm for each check and add variety between releases. Add variety by returning information from the server that can be decrypted using various hashing algorithms in addition to the section that is decrypted via RSA or by using multiple RSA key pairs that are used in different parts of the codebase.
Scarcity: Include some verification checks on rare conditions, with only basic checks happening consistently on startup. With scarce checks, hackers may produce only partial cracks of the software. Users of these cracks may still be prompted to download the software legally when one of the rare conditions is satisfied.
Isolation: Checks should not reference the same underlying variables. If multiple verification checks must reference the same variable, dynamically resolve references by calculating the address of pointers to important data at runtime.
Integration: Integrate license checks with important sections of code. Write code such that unexpected behavior will occur if the license check doesn’t execute. Integrations can occur on the message thread, on file reads, and in the set-up code on the audio thread. Be careful about preserving real-time safety when integrating checks on the audio thread.
What do you do if the server that validates license files is unable to send or receive messages? My position is that users should be able to run my plugins without verification if my server is down. For those who agree, consider the following method. Check the users internet connection; if the user is connected to the internet but is unable to access your server, consider letting them use your plugin without verification. This way, the software will function long into the future even if the server stops running.
One reason to crack a plugin is to test it if it does not offer a free trial. Consider implementing a free trial plugin so that customers can be confident before they buy. This may reduce the frequency of illegal downloads of the software. Be careful though, all of the data rights management tips that apply to license verification apply to free trial software as well. Make sure that there is no single point of failure in the code that would allow bad actors to bypass the trial.
If setting up a secure data rights management scheme sounds like too much work, or otherwise does not align with your priorities, there a few other options short of releasing a plugin with no DRM at all.
Nagware is perpetually free to use software that periodically asks the user to pay if they have yet to verify. In a nagware scheme, the goal is not to completely prevent cracks. Instead, the goal is to provide a safe and easy to access free version of the software that will convert users into paying customers over time. Because of this, any data rights management in a nagware scheme can be extremely lightweight. Crackers will be unlikely to go through the effort of removing nagware, as they can already access all of the functionality of the plugin for free. Examples of nagware include the popular DAW REAPER and the popular text editor Sublime Text.
Distributing a finished plugin can be surprisingly frustrating – it’s
worth setting aside at least a few days of work to get everything
together before release. In The Template Plugin, I include a script,
notarize.sh, which can help package a plugin for
distribution on MacOS. The following section walks through the process
of preparing a plugin for distribution.
Both JUCE and Steinberg’s VST3 format are dual licensed under GPLv3 and a commercial license. Thus, there are two options when distributing a plugin: release the plugin open source, under GPLv3, or go through the process of obtaining commercial licenses from both JUCE and Steinberg and release the plugin closed source.
The GNU General Public License version 3.0 is a “free, copyleft license for software and others kinds of work” [13]. This license protects software under copyright law. However, users of GNU GPLv3 must also release a public copy of their source code. Furthermore, they give anyone the right to copy, modify, or redistribute the software. While developers retain the right to sell their software for whatever price they want, another person could copy the code and sell their own version of the software for any other price.
Releasing open source comes with fewer headaches. First of all, releasing open source is free. There is no need to pay JUCE for a license, which costs upwards of $800 at the time of writing. Furthermore, one need not contact Steinberg to obtain a commercial license. And, one may opt to forgo data rights management as well in an open source plugin.
The main downside to releasing under GPLv3 is that there is no way to require that anyone who receives the plugin also pays a fee and notifies the developer. This makes it hard to commercialize GPLv3 licenses at scale. Still, open source is the most lightweight way to release a plugin, and can be useful for researchers and those who are not as concerned with profiting off of their plugin.
To release open source, simply include the GPLv3 license in each source code file and post the code publicly. Then, distribute the plugin binary. Equivalently, one could bundle their source code with the plugin binary upon distribution. GPLv3 requires equivalent access to source code and binary, meaning that any fee to download the source code may be no more than the fee to download the software itself.
Those who would like to profit off of their audio plugins will likely want to release closed-source with one of JUCE’s commercial licenses. JUCE has four commercial license tiers: educational, personal, indie, and pro. While both the educational license and personal licenses are free, they require a “Made with JUCE” splash screen notice every time the plugin is opened. Since I want my plugins to look professional, I prefer to forgo the splash screen.
The indie JUCE license makes the most sense for small developers looking to turn a profit. It is $800 for a perpetual JUCE 7 indie license and is capped at a $500k annual revenue limit. If you make more than $500k a year on your plugin, you can opt for the $2600 professional license.
Releasing VST3 plugins closed source also requires written permission from Steinberg Media Technologies GmbH. One can contact them about this via land mail or email as outlined on their website. In my case, it took them over a month to return a countersigned license agreement, so plan accordingly. Furthermore, to comply with their license, you must acknowledge Steinberg in your plugin documentation.
If you plan on releasing plugins for Avid ProTools, you must compile plugins for the AAX format. In order to do this, you need to obtain a copy of the AAX software development kit from Avid. Furthermore, you must comply with Avid’s commercial license which requires written permission from Avid. The details of this process are subject to a non-disclosure agreement. In my own work I have chosen not to release plugins for ProTools; compiling to AAX and complying with Avid’s licensing adds too much additional complexity to my development pipeline given that only a small portion of my audience uses ProTools.
Once your plugin binaries are ready to go, and you’ve complied with all the necessary license agreements, you may be eager to post your product online. However, most operating systems and many browsers flag unidentified software as viruses. At best, users will be warned before downloading your software. At worst, the operating system will make it impossible to run your software at all. In order to pass these anti-virus checks, you need to attach your name to the software you are distributing as meta data. Furthermore, you must register yourself as a known entity to the operating systems you are targeting. This process is called notarization, and can be accomplished via code signing. Both MacOS and Windows require that you pay a fee to notarize your software.
Host programs look for VSTs in special folders on the user’s computer. The easiest way to make sure that a program ends up in the right folder on a user’s computer is to distribute the plugin in an installer. Installers copy the plugin binaries to the correct locations on the users computer and present important information about the plugin, such as the end user license agreement and a simple README file.
There are many tools for creating installers on MacOS. Since I prefer
to wrap codesigning and installer creation into a single bash script, I
choose to create packages with the pkgbuild and
productbuild command line utilities. If you prefer
interacting with a GUI, you can use a number of free software programs
such as Packages.
The pkgbuild command line utility creates simple .pkg
installer files for each of the binaries to be installed. Then, the
productbuild utility synthesizes many installers into a
single file. productbuild can also include an end user
license agreement, welcome message, README message, and background image
in the installer.
For the exact commands I use to create my installer, see
notarize.sh in The Template
Plugin.
To code sign a plugin for distribution on MacOS, you must enroll in
Apple’s Developer Program for $99 per year. Joining the Apple Developer
Program allows you to code sign your software and pass Apple’s antivirus
software. Once you join the Apple Developer Program, you must generate a
Developer ID Application Certificate, which you will need to pass to the
codesign and productsign command line
utilities. Furthermore, you must generate an App Specific Password which
you will use to notarize the final installer using the
xcrun command line utility. You can generate an app
specific password from your
developer account
page.
Once you have collected all of the necessary materials, run
codesign -s on all of the individual plugin binaries that
you are planning to distribute. Then, run
productsign --sign on your installer. Finally, notarize
your installer with the xcrun altool --notarize-app command
and your app specific password. Wait a few minutes, and you will receive
an email from apple letting you know if notarization was successful. If
notarization was successful, run the following code on your installer
file and you are finished.
sudo xcrun stapler staple YOUR_INSTALLER_FILEFor the exact commands I use to notarize my software, see
notarize.sh in The Template
Plugin.
For my own plugins, I do not create installers for Windows. Distributing installers on Windows requires code signing with an Extended Validation (EV) code signing certificate, which can cost $400-$1000. Without an EV certificate, Windows installers may display a malware warning and may be difficult or impossible for users to run. Note: the cheaper “OV” certificate is less reliable and can still be blocked by anti-virus software. To make matters worse, EV certificates are only available from third party vendors and are typically stored on hardware usb sticks. The whole process of obtaining an EV certificate and signing your plugin installer is confusing and can take weeks to months of time.
Instead, I distribute my plugins in a .zip folder containing the VST3 file as well as a manual and instructions for installing the VST3 in the correct system folders. This method creates a little more friction for the user who is downloading my plugin, but has worked well enough for me so far. Notably, I have not run into trouble with anti-virus software using this method.
If you have an EV certificate and would like to go ahead and create an installer for Windows, you can use the free software Inno Setup. The JUCE website has a tutorial that walks through the steps of creating an installer this way.
Notarization is one of the most frustrating aspect of plugin development. Try confirming the following if you are stuck:
Release mode with
HARDENED_RUNTIME_ENABLED TRUE set in your
CMakeLists.txt filexcrun stapler command after successful notarization.If all else fails, you may find the following commands useful on MacOS for checking the notarization status of a file.
# To see notarization logs after receiving an email that notarization has failed:
xcrun altool --notarization-info NOTARIZATION_REQUEST_ID -u APPLE_ID -p APP_SPECIFIC_PASS
# Various commands for checking notarization status of a file:
spctl -a -vvv -t install "INSTALLER_FILENAME.pkg"
codesign -vvvv -R="notarized" --check-notarization PLUGIN_BINARY_FILENAME
codesign -dv --verbose=4 karp.vst3An end user license agreement (EULA) grants users the right to use your plugin. The main purpose of this document is to legally protect the software developer from copyright infringement, lawsuits, and misuse. It is important to include any specific actions that are not permitted upon gaining access to your software. For example, if you only allow users to activate your plugin on up to a certain number of machines, you should include that number in the EULA. EULA’s can also explicit prohibit actions that might lead to the creation of illegal copies of the plugin, such as reverse engineering and decompiling. I include an EULA bundled with my plugin when it is downloaded. I also prompt users to accept the license agreement when they install my plugins via an installer.
Most plugins should come bundled with a manual, which outlines the function of each of the user interface elements and sheds light on the underlying digital signal processing of the software. Manuals should be available before the plugin has been purchased, giving potential users more confidence in the functionality of the plugin. Manuals should be as comprehensive as possible so that users can operate the plugin to its full potential without having to seek external guidance.
Many people also look for demo and tutorial videos before purchasing a plugin. Having a demo video that shows how the plugin can be used and how it sounds allows potential customers to have confidence in the product they are buying. It is generally a good idea to make demo and tutorial videos accessible from the site where your plugin is available for purchase.
In Halo 3D Pan, I use raymarching to render the 3D user interface [54]. Raymarching enables real-time 3D geometry, lights and shadows, camera movement, and animation. Furthermore, with careful implementation it is possible to enable direct mouse interaction with a raymarched UI.
In raymarching, each pixel is a simple function of its position on the screen – all of the 3D geometry is derived from pixel coordinates and computed by a pixel shader. This is done by simulating rays from a virtual camera into a scene. By repeatedly stepping along the ray until the distance to the nearest object is under some threshold, we can determine the position of the object that the ray intersects. In order to compute the distance to the nearest object in the scene, we define a signed distance function (SDF). The signed distance function computes a value for any point in 3D space that represents the distance to the nearest surface of an object in the scene. If the point is inside the object, the value is negative; if the point is outside the object, the value is positive. Given the 3D position of intersection between the ray and the scene, we can compute the surface normal, shading information, and finally the color of the pixel. We speed up computation in raymarching by moving towards the object in steps sized by the distance to the nearest point on the object.
To alter the 3D scene, we can pass parameters into our shader called uniforms. Examples of uniforms include time, mouse position, audio loudness, and images. When we pass parameters to our shader as uniforms, we enable the geometry of our scene to adapt to our program’s state. An example of this might be changing the position of a slider when the user moves a corresponding parameter. What if we want the user to be able to directly interact with the scene by clicking and dragging with the mouse? How do we make changes to our parameters given mouse interactions? The solution is to render a scene in the background where the color of each pixel represents the type of mouse interaction that happens when that pixel is clicked. For example, the color of a knob in the background buffer should tell the program which parameter that knob controls. Since reading the color of the pixel under the mouse determines whether the user interacted with a particular knob or slider, we can apply mouse drags to corresponding parameter changes.
There are several downsides to raymarching plugin UIs. For more complex programs with large user interfaces, raymarching may be prohibitively expensive to compute on the GPU, resulting in a laggy interface. One way to get around this is to dynamically reduce detail-level, resolution, and anti-aliasing features of your shader if the user’s computer cannot hit a certain frame-rate. Furthermore, certain mouse interactions are more difficult to perform in a raymarched UI. For example, it may be difficult to implement a rotary knob where the parameter value depends on the angle between the mouse and the center of the knob. Furthermore, text is difficult to render with raymarching, and usually requires a special font texture. One way to get around this is to use a heads-up display for displaying text on top of the OpenGL scene using traditional UI methods.
Despite these downsides, raymarching enables complex real-time graphics that are difficult to achieve with CPU-based methods or even other GPU-based 3D rendering techniques. Raymarching doesn’t usually require large image files, making it very lightweight. Furthermore, OpenGL UIs can be easily ported to the web with WebGL. And, 3D UIs can be much more dynamic than traditional interfaces – enabling camera movement, dynamic 3D lighting, post-processing shaders, and audio-reactive geometry.
To download The Template Plugin, clone the repository from GitHub. Update submodules to get a copy of the JUCE library in the same folder.
git clone https://github.com/ncblair/NTHN_TEMPLATE_PLUGIN.git
cd NTHN_TEMPLATE_PLUGIN
git submodule update --recursive --init --remoteAlternatively, if you would like to set up your own git repository
with the code from The Template Plugin, you can create a new repository
from a template using the github CLI tool gh.
# If this is your first time using gh, install it and log in
brew install gh
gh auth login
# create a (private) repository based on the template
gh repo create my_new_juce_proj --template ncblair/NTHN_TEMPLATE_PLUGIN --private
# clone the template repo locally
gh repo clone my_new_juce_proj
# update submodules to get JUCE code locally
cd my_new_juce_proj
git submodule update --recursive --init --remoteFirst, open CMakeLists.txt in a text editor. Set your
plugin name, version number, version string, company name, manufacturer
id, and plugin id at the top of the file.
On MacOS, open build.sh in a text editor. Set the plugin
name and build mode at the top of the file. Use the same plugin name
that you used in CMakeLists.txt. Possible build modes
include Debug, Release,
RelWithDebInfo and MinSizeRel.
Then, run the build script
./build.shOn Windows, run the following code:
mkdir build
cd build
cmake ..
cmake --build . # (--config Release/Debug/...)If compiling was successful, you should already be able to run the plugin in your DAW of choice. Simply open your DAW and search for your plugin name. By default, the plugin will be called EXAMPLE.
To run the plugin as a standalone application, run the file found in build/EXAMPLE_artefacts/Debug/Standalone/EXAMPLE.app
By default, you should see a green background with a single slider that modulates the gain of the incoming signal.